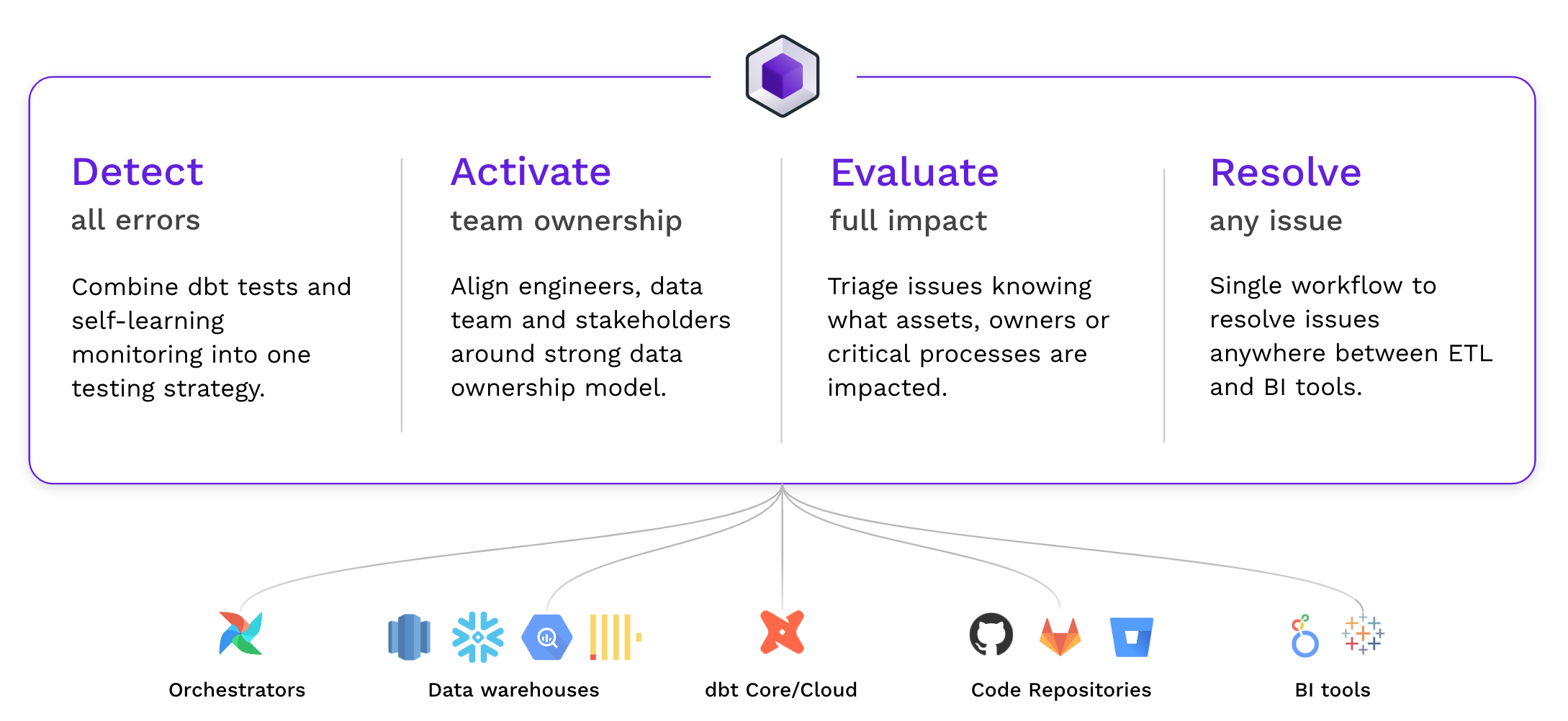
New capabilities to manage data reliability at scale

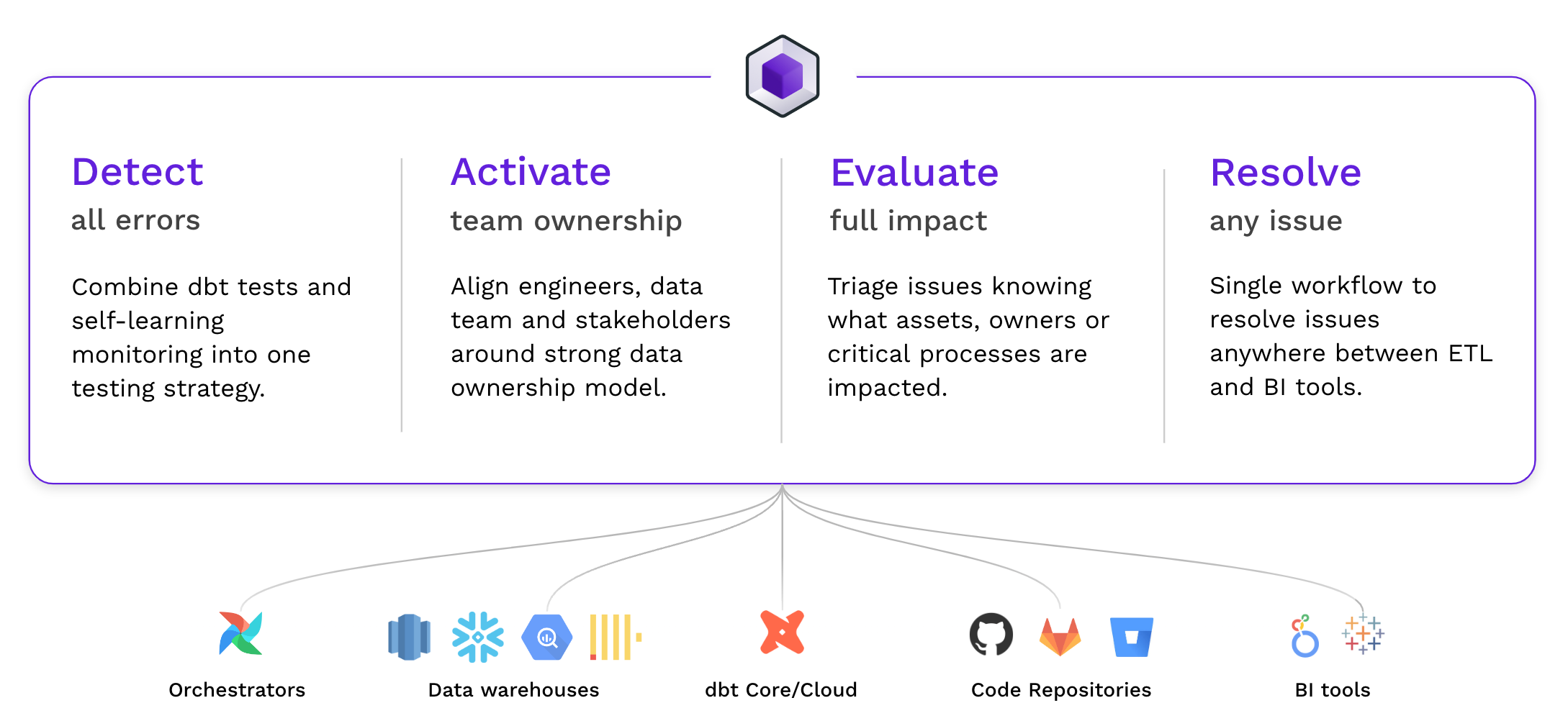
At Synq, our mission is to empower organizations to extract value from their data. But that can only be done if the data is trusted. That’s why we’re dedicated to building a comprehensive set of tools that allow data practitioners to manage their data reliability with confidence. With tools that are on par with those used by their software engineering colleagues.
Starting with strong ownership
We took a first step by focusing on three key concepts: Ownership, critical data and alerting.
We did so with a belief that at the heart of every data ecosystem is a team of people responsible to build and operate their data platform day to day. Without clear ownership and understanding which of hundreds of data models are critical to the business their job is too hard.
We linked both ownership and management of business critical data to alerts that can be routed to teams, tagged with relevant people, packed with relevant information about what exactly failed and what could be the root cause.
But this was just the beginning.
Detect errors without fragile manual thresholds
With the complexity of data in today’s modern organization, detecting errors is more complex than ever. Luckily many teams have invested in solid testing suites for their data, especially in dbt, but we wanted to help more.
The new Synq monitoring is a self-learning testing engine that learns from historic patterns in data and dynamically applies thresholds that detect anomalies. It automatically monitors the volume and freshness of data and offers the capability to define more granular custom monitoring rules to complement dbt tests.
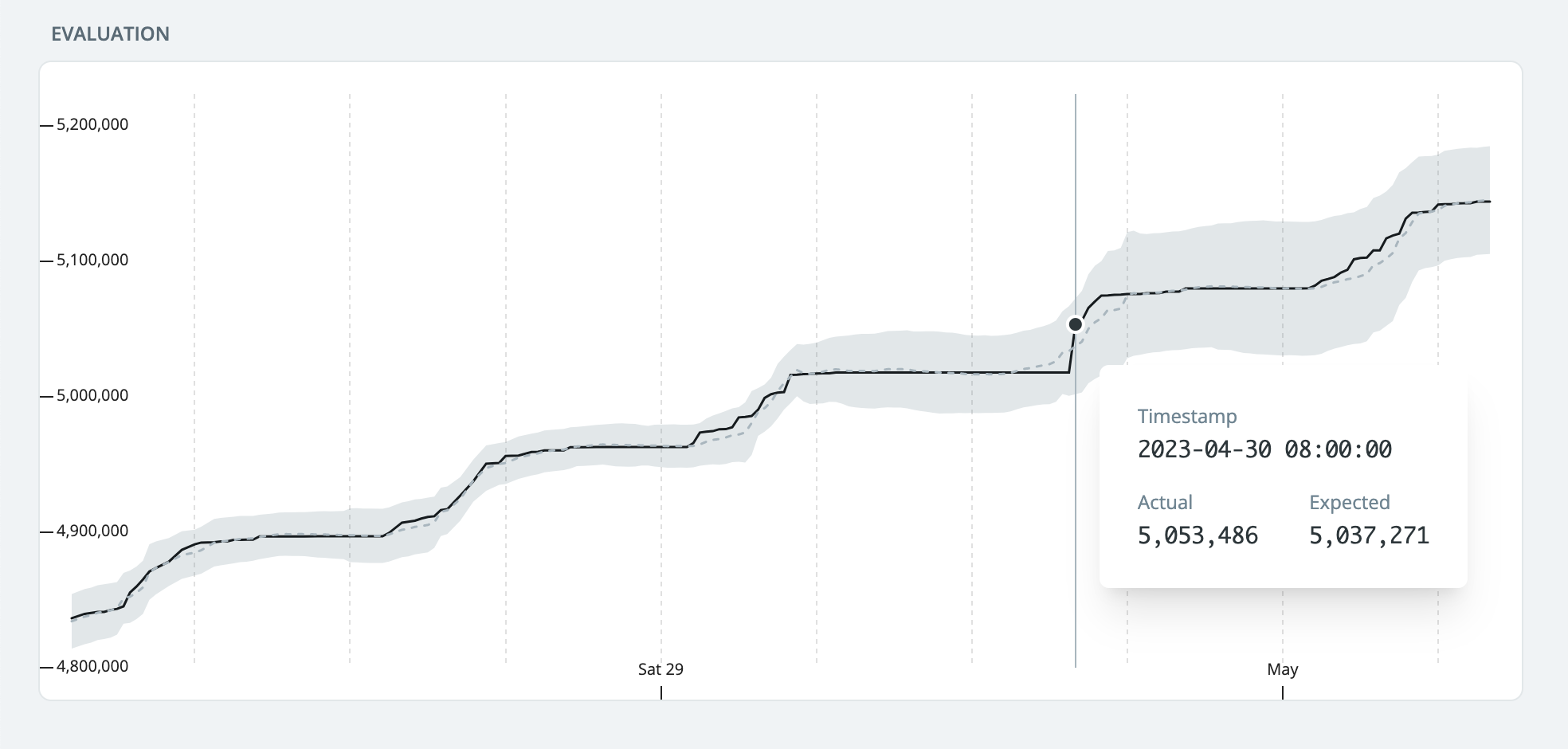
To deliver the best experience that minimizes false positive alerts, we have created a multi-stage prediction pipeline that can detect complex patterns with long-term trends and weekly or intraday seasonality that reflects your business. In the consequent stages, we apply multiple thresholds to see various anomaly patterns such as spikes, level shifts, or more slowly changing ways that build over a long period.
We plug the monitoring engine into everything else. Monitors can be assigned owners and routed to relevant teams alongside other test failures. We’ve built a monitoring engine to work well with your testing.
The best strategy to detect errors combines both automated tests and self-learning monitors. We want to support teams by integrating both into one overall testing strategy.
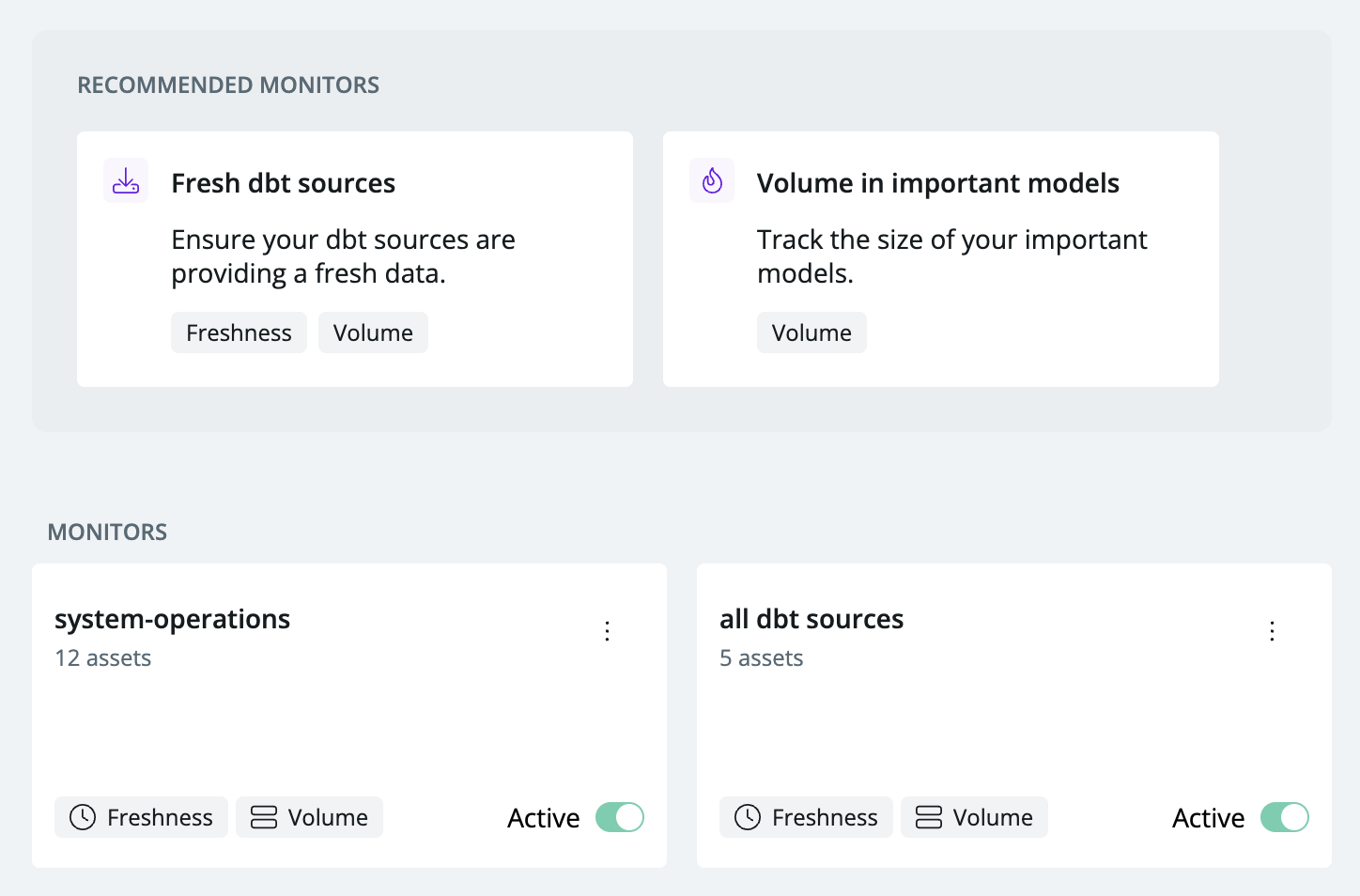
Synq monitors can be set up based on any of your metadata. It’s straightforward to deploy monitors to tables that dbt Sources use or to deploy monitors on models with specific metadata or tags. This gives you complete control and an efficient way to deploy monitors where they can help detect errors the most, complementing your dbt tests.
From alert to impacted owners in a click
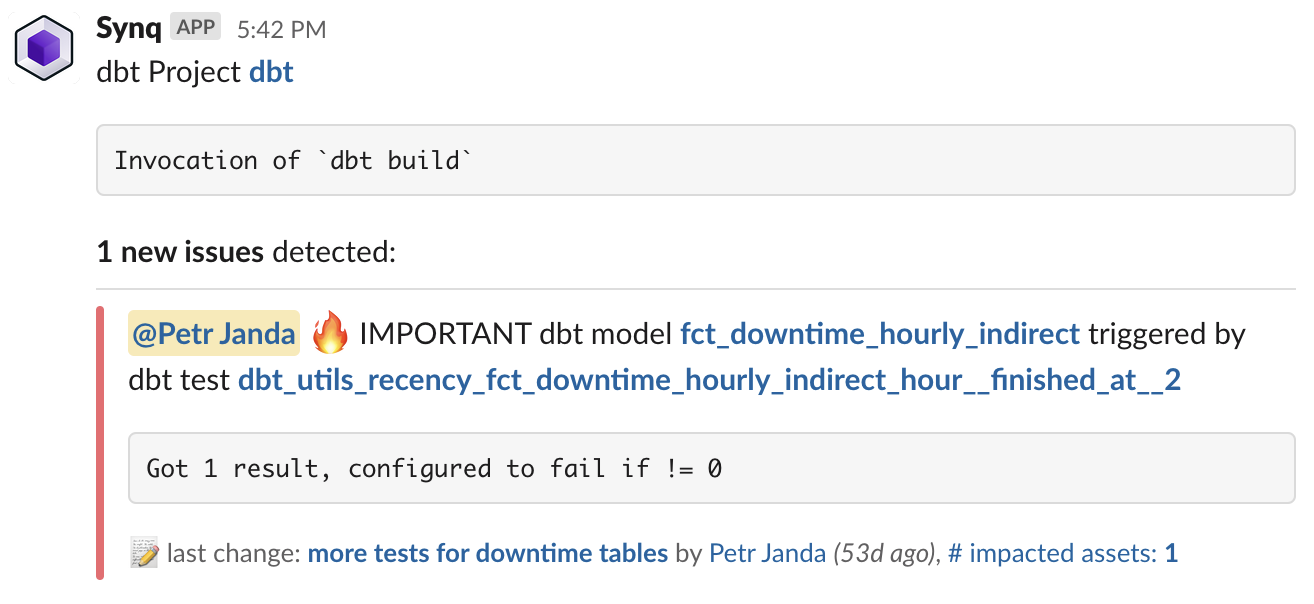
With strengthened tooling to detect issues, we next focused on managing incidents. To support data practitioners through these stressful moments, we have developed a new incident management workflow.
Since any incident can potentially cause a severe business impact, we empower the person responsible for triaging alerts with all the necessary information to evaluate the incident.
The new functionality combines lineage, ownership, and critical data management to create a clear incident impact summary.
You can easily answer the following questions:
- What data assets downstream are impacted?
- Does the failure have a business critical impact?
- Who is impacted?
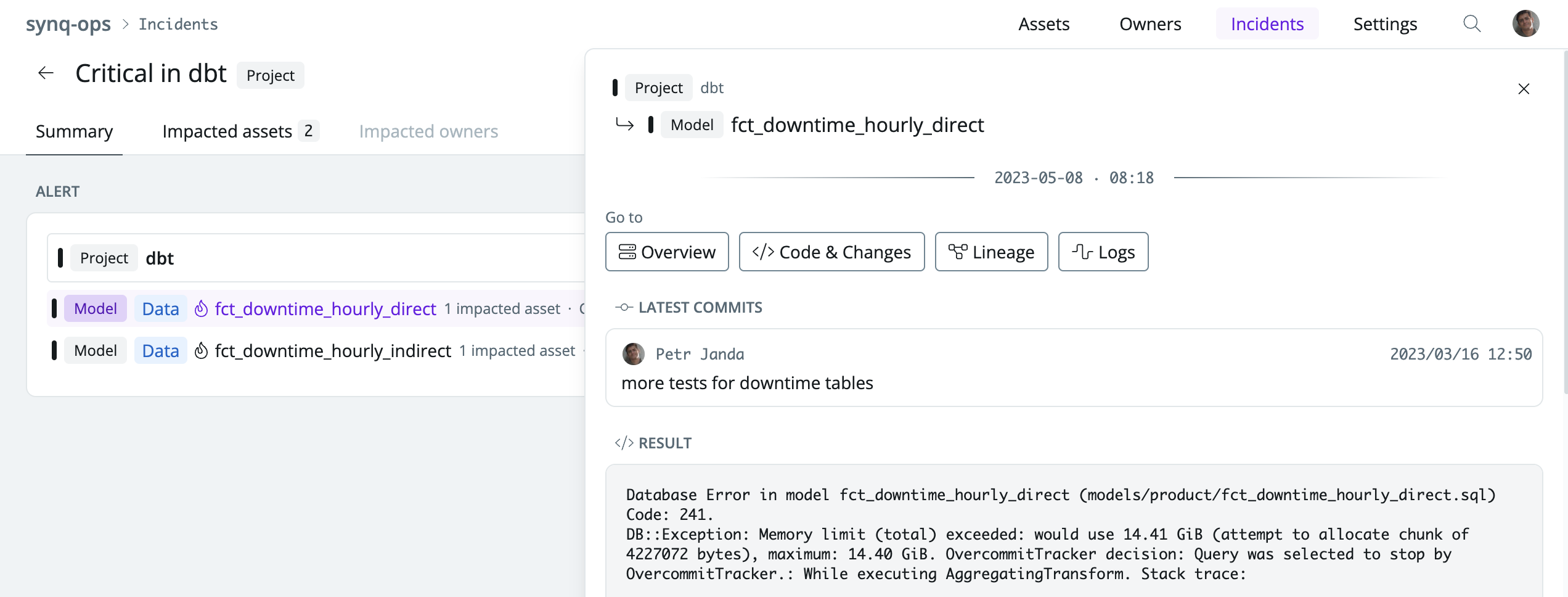
From the summary, you can dive into the details to see the impact of the owner to understand who needs to be notified and what would be the most appropriate message.
Incident management workflow also makes it much simpler to review all failure messages, zoom in on the latest code changes, and monitor results to identify the root cause. All from one interface.
Supporting model-centric analytics workflows
When we build software, we model our systems around services, not files. The Analytics ecosystem is going through the same transition. With concepts like models, metrics, model groups, or data products, we are gradually moving away from a table-centric view of the data stack. We are excited to support new dbt 1.5 concepts such as model groups, contracts, or private models support teams that build their data stack at scale, enabling use cases such as:
- Targeted alerts to defined group owners
- Measure the uptime of models/tests for asset groups
- Understand upstream/downstream dependencies of groups
- Or alert on violated contracts relevant teams
We build for teams who adopt the model-centric point of view.
Synq—a data reliability platform for modern teams
With new integrations to Airflow, Snowflake, BigQuery, Redshift, Clickhouse, dbt 1.5 and new workflows we have expanded Synq capabilities to support teams on their journey to reliable data, helping detect all errors, activate the ownership, evaluate the impact, and resolve any issue before they cause any harm in the business.
We’re excited to expand our platform and support teams with their reliability workflows end-to-end.


