Helping data teams improve reliability of their critical data

“Holly s**t, there are a lot more models than there used to be!” —Tristan Handy, dbt Labs at Coalesce 2023

DAG of dbt Labs internal analytics project
The data stack has expanded, with 6,000+ teams deploying data stacks containing 1,000 models or more. Tens of thousands of data practitioners might echo Tristan’s sentiment. Perhaps you’re among them?
As we encounter new applications for data, where analytic datasets not only inform but also power critical business operations and customer-facing products, a new challenge emerges: managing complexity and ensuring reliability at scale while meeting business-critical standards.
Software engineers have been through a similar path. Particularly in the past decade, we’ve witnessed the formation of distributed software platforms built on top of containers and microservices. Although the current state of software engineering is far from flawless, engineers made significant progress by adhering to one key principle: breaking down complex systems into smaller, more manageable parts.
The question then arises: How can we apply this principle within the realm of data?
Managing complexity is undoubtedly at the forefront of dbt Labs’ strategic roadmap. At the dbt Coalesce keynote, concepts such as model groups, versioning, contracts, private models, and multi-project deployments were highlighted as innovative solutions for complexity management. These concepts resonate deeply, as they mirror a microservices-oriented approach that advocates for systems decomposition.
At Synq, we’ve encountered similar complexities with our clients and have honed our focus on another pressing issue that data teams face when constructing systems at scale:
- How do we identify the most vital assets within our data ecosystem?
- How can we segment these critical elements from the less important assets?
- How do we know they work correctly?
- And crucially, when problems arise, how do we fix them?
We’ve set out to address these questions with our product.
Synq Data Products
The idea of data products isn’t exactly new. The Data Mesh movement pioneered data products to emphasise that well designed data for a specific business use is a product. Like any other software.
Data Product has its customers, use case, reliability expectations, owners or SLAs. At least if managed well.
However, relatively few tools exist to integrate data products into the daily workflows of data practitioners. This is where we’ve spotted an opportunity to forge a new mindset. We aim to practically conceptualize what a data product is and explore how it can be employed to address some of the persistent challenges associated with managing data on a large scale.
Create more Clarity
When a data platform scales to hundreds or thousands of assets, it becomes too complex for the human brain to manage. It’s impossible to keep track of all the intricate connections.
”I use a set of tables to train ML models that drive allocation of vehicles we use to run our business. I have some sense of what is upstream, but it’s 100s of models which means it’s really hard to track all changes and if everything works.” —data scientist, logistics company
”I am responsible for a set of our core models that we provide from our product team, but I don’t have a full picture of how all our data is used downstream.” —data analyst, the same logistics company
It’s a widespread issue.
Most teams managing a large data stack are spread out within their companies and don’t have a clear picture of where the most valuable data is in their stack, or how it’s being used. As teams create more projects, organise models into groups, or establish contracts, this lack of clarity will persist. Some parts of our data platforms are crucial to the business, while others may not be— at least not right now.
You might be thinking, that is what we can solve with data lineage. Well, not really. At least not on its own. Lineage views make thousands of tables look the same, indistinguishable from one another. Without extra tools and metadata, teams can’t grasp the full meaning of the lineage, especially when it’s as complex as what Tristan presented at dbt Labs.
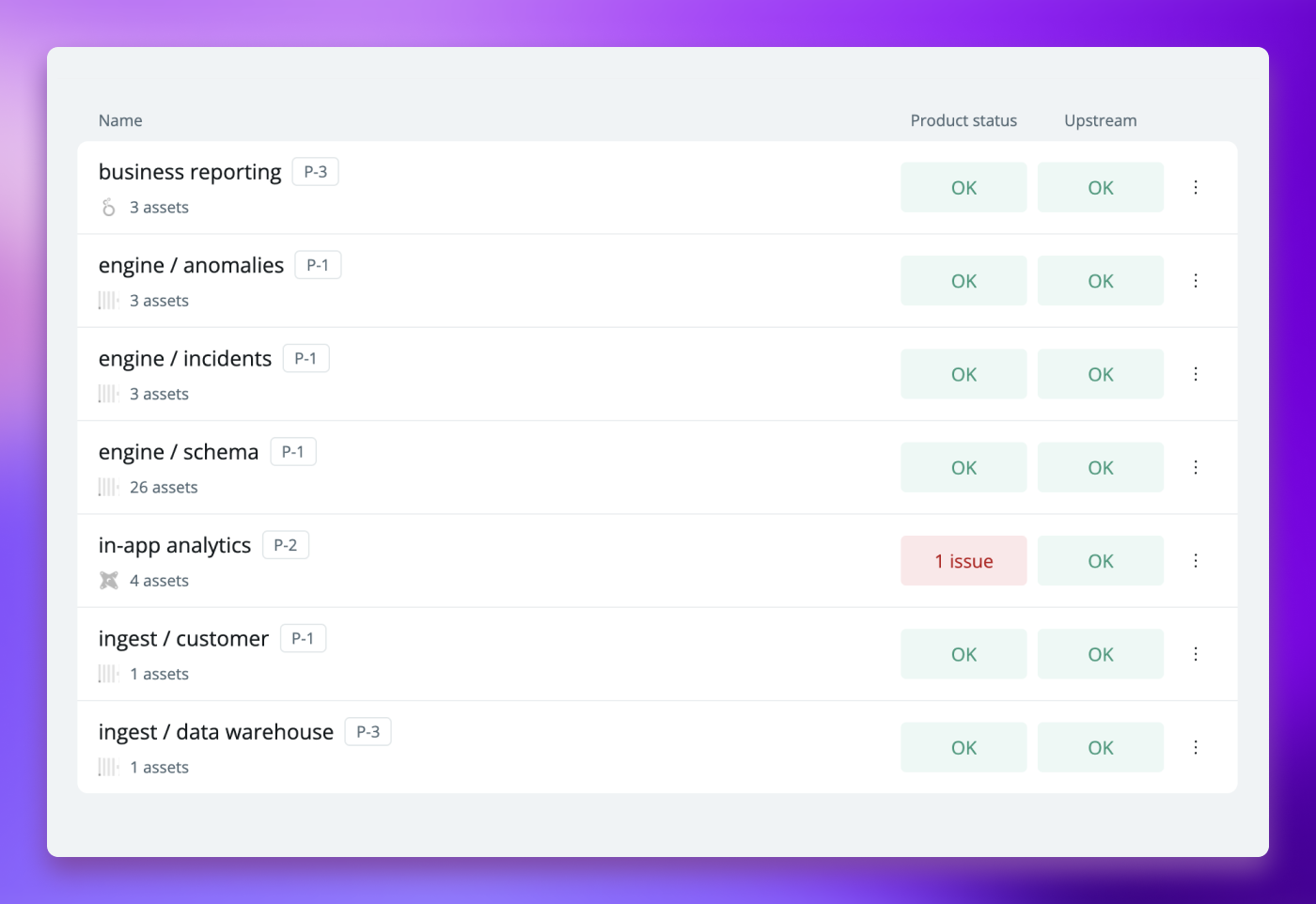
That’s where Synq steps in, starting with clarity. Our customers can define one or several data products that are either linked to a particular data-producing team (source-aligned data product) or to a specific business use case (consumption-aligned data product).
A data product is defined as a set of data assets—including tables, models, metrics, dashboards, and pipelines—that are semantically connected and centered around a shared purpose.
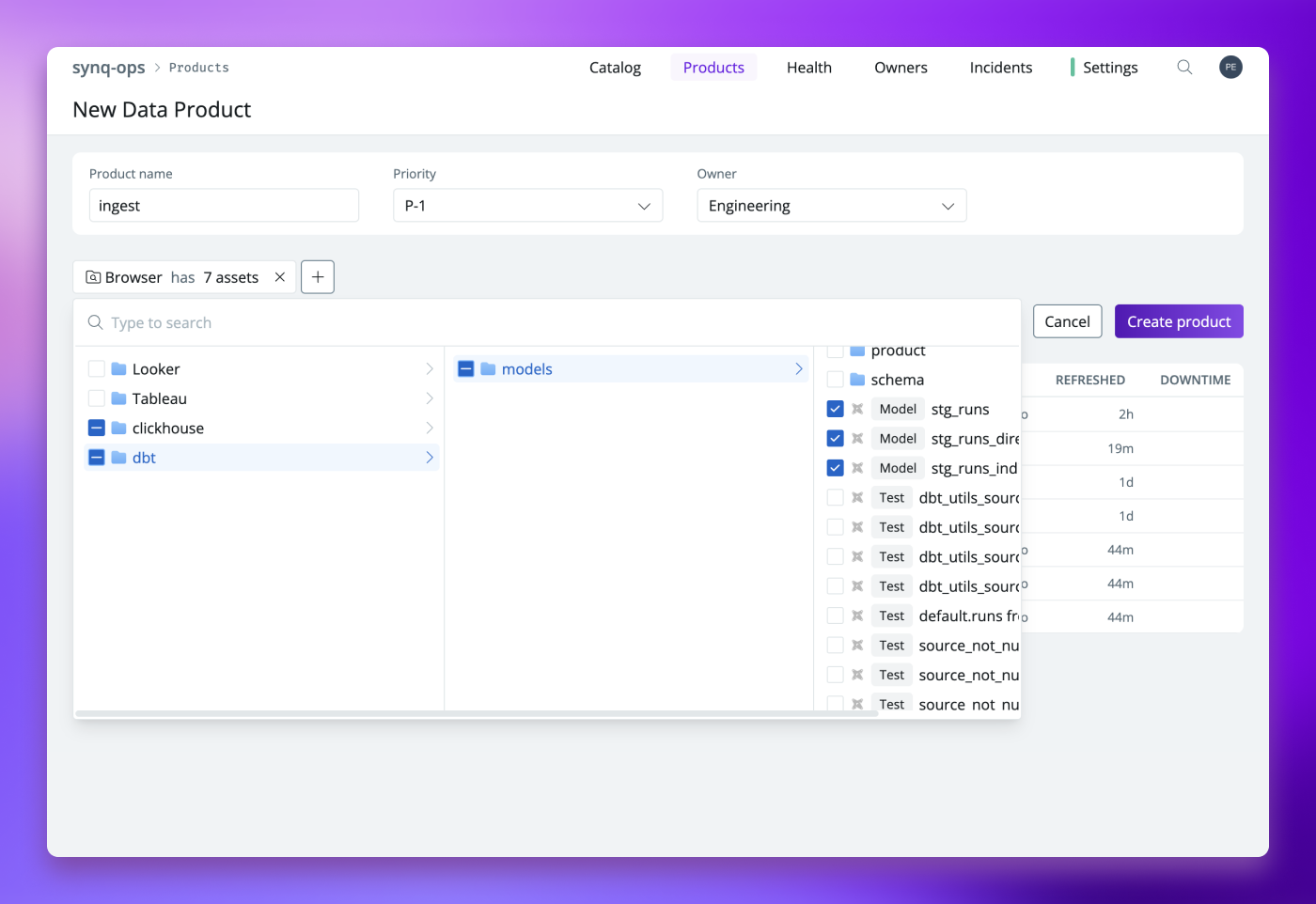
Example data product defined as a combination of assets across ClickHouse tables and dbt Models and Sources.
Our metadata infrastructure enables our customers to define a data product in various ways, such as:
- A set of dbt models and metrics within a specific dbt folder, like a finance mart.
- A group of dbt models linked by an exposure, for instance, models used by a CLTV model that powers marketing automation.
- A selected collection of dashboards in a BI tool, such as core KPI reporting.
- A compilation of tables or dbt models that carry a common tag, like all ‘P1’ models that require high-priority management.
The definition of a data product is dynamic, so any new assets meeting the criteria — be it a particular dbt group, tag, or location in a folder or schema — are automatically included. This eliminates the need for manual tagging and the risk of discrepancies.
By establishing data products for critical segments of the data stack, teams gain a clearer understanding of what data is most important and how it connects with other assets, both upstream and downstream. This clarity is what we aim to deliver.
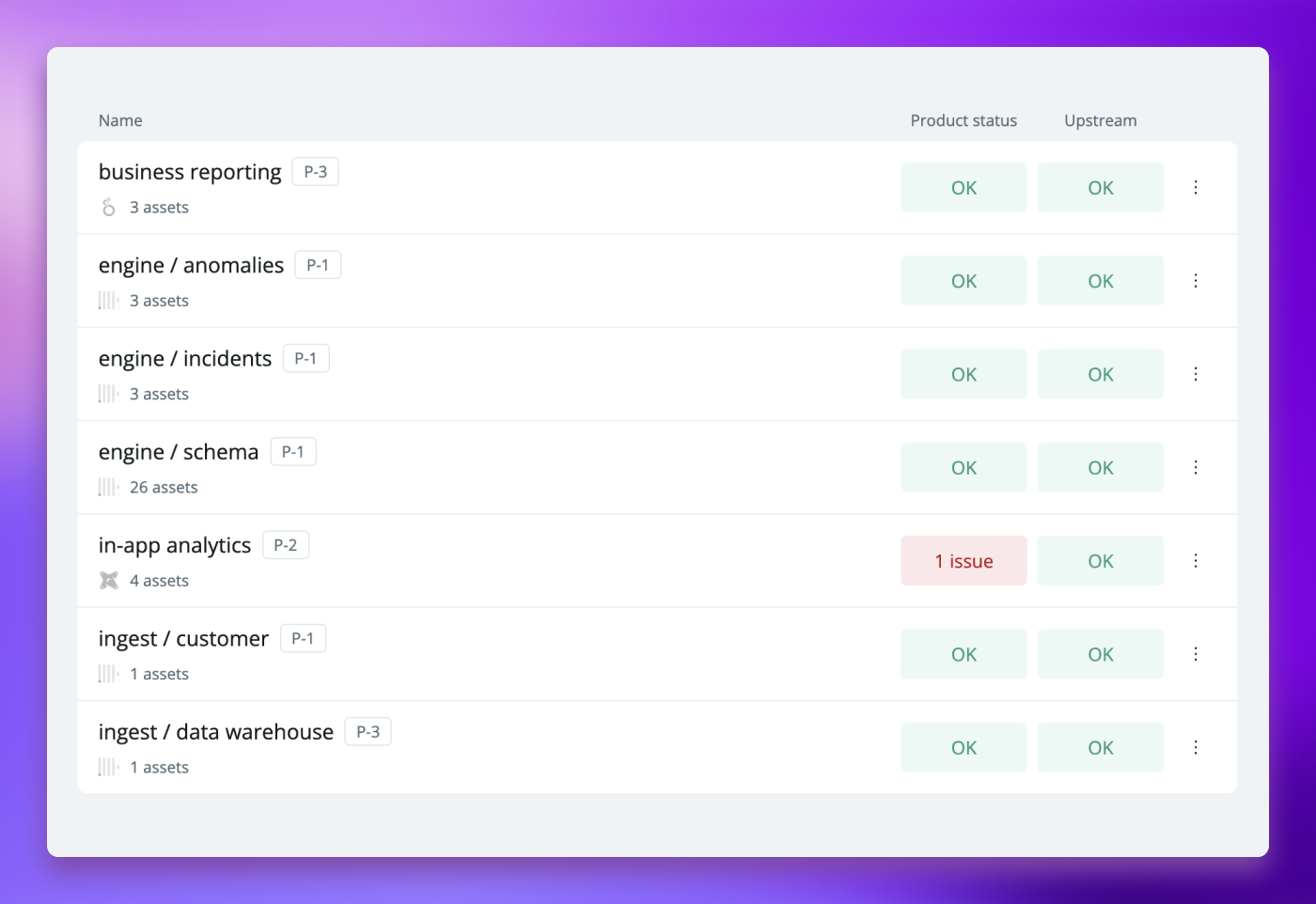
Overview of internal Synq data product spanning assets in dbt, clickhouse and Looker.
Foster a sense of Ownership
Data stacks are managed by people working in teams. When there are hundreds or even over a thousand models, it’s rarely just one team’s job. The structure of the data team often resembles an octopus: a central data (platform) team extends its tentacles throughout the organisation. Data analysts, scientists, and analytics engineers are typically positioned close to where data is produced and consumed—across departments like product, finance, revenue, operations, or marketing.
Each team is responsible for a portion of the data assets, either contributing data to the platform or using the data in a way that’s often vital to the business.
We’ve designed data products with a simple ownership model: every data product has a single, clear owner. This clarity fosters a sense of responsibility within the data stack.
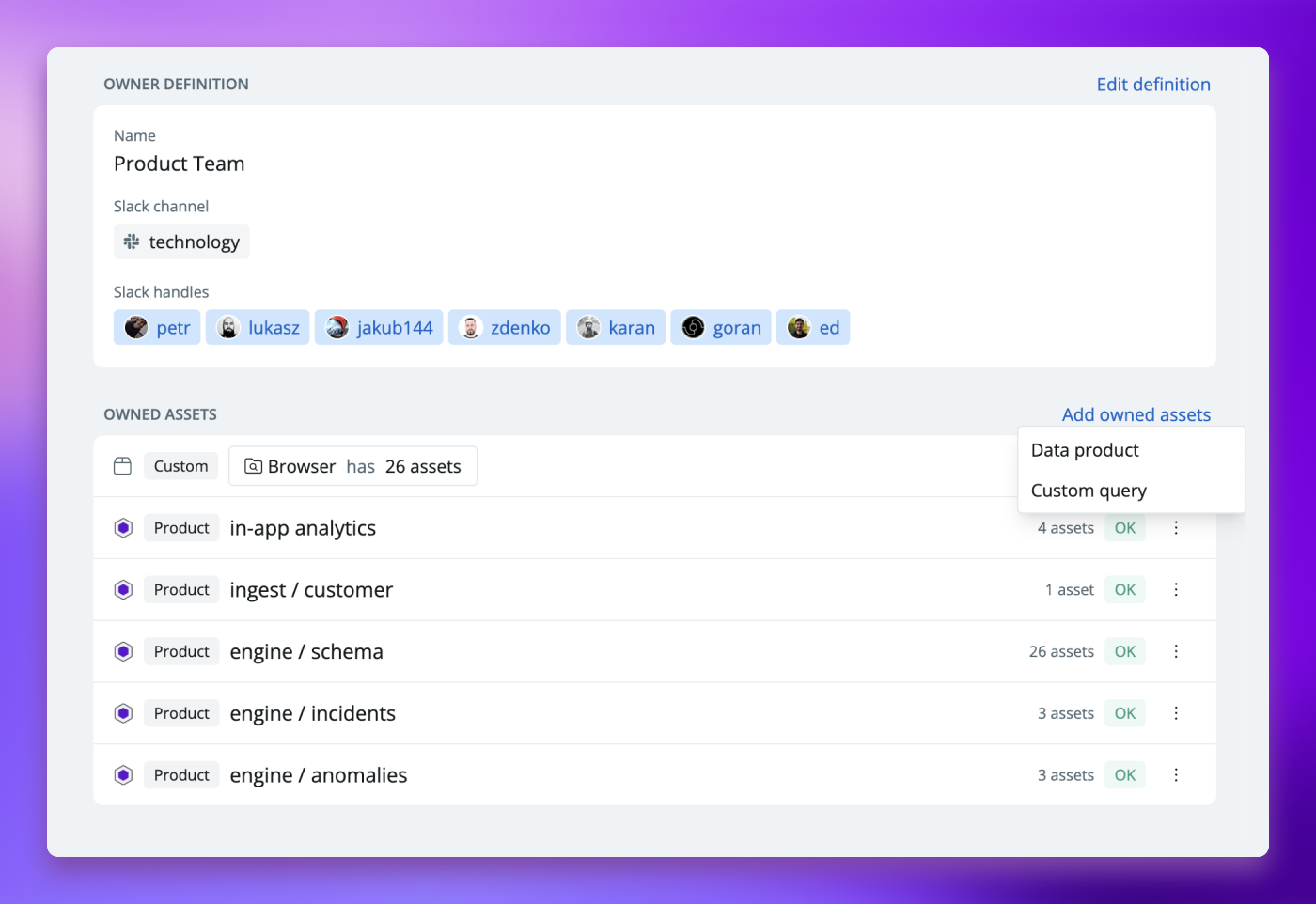
Define and operationalize relationship between people, their teams and data products they own.
From there, the rest of Synq’s functionality kicks in.
Owners are alerted to any issues within their data product. They can also choose to get notifications about problems with data upstream—a useful feature for ML engineers who might not realize one of their dbt sources has just failed a freshness test.
Owners can see overview of everything they are responsible for and understand who are the owners of critical data downstream. Synq not only clarifies ownership but also activates new workflows that help owners stay informed about the health and status of their data products.
Strengthen the Reliability
With thousands of models, hundreds of data sources, and a vast array of data consumption scenarios, failures are a given in any large and complex system.
Yet, not all failures carry the same weight. Consider two situations:
In the first, a new data pipeline recently hooked up to the data warehouse is delayed. Alerts are triggered, but it’s not a major issue—there’s nothing critical depending on it, maybe just a few tables tied to some dashboards still under construction.
In contrast, the second scenario involves a failure in one of the data sources critical to downstream operations. These connections are not always evident.
Even teams diligent about tagging their most critical data paths can quickly find their efforts lagging behind the ever-evolving business and its data needs. One overlooked new link can lead to significant business disruptions.
This is where the concept of data products becomes central to reliability. By adding semantic meaning to the data through its business priority, we enable more effective workflows:
- An analyst alerted to a dbt freshness issue instantly understands if a crucial business process, like the marketing pipeline, is at risk.
- The data product owner is promptly informed of upstream issues—this can even be integrated into BI tools.
- Identifying a critical data product paves the way for targeted data testing strategies. With Synq, volume and freshness monitors can be dynamically applied to all dbt sources that feed into top-priority data products. New data sources connecting to critical downstream data will automatically have monitoring set up.
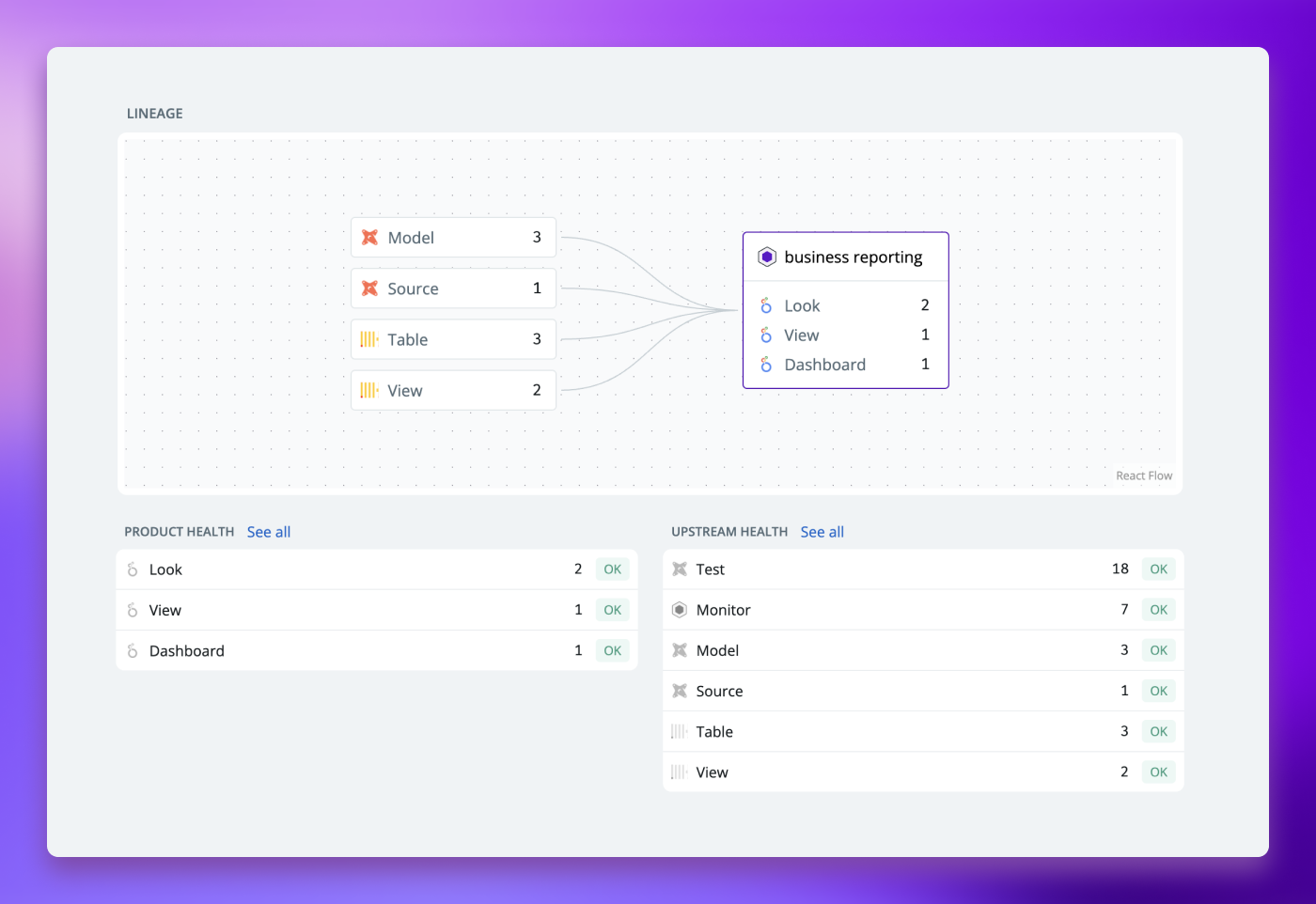
Understand upstream dependencies of your critical data and get up to date state of all models, sources, tests or monitors.
Data products serve as a robust tool to pinpoint where in your data stack to focus on reliability and enable teams to swiftly address the most pressing issues.
The path forward, get in touch!
We’re developing an array of additional features. Data products will integrate with incident management and SLA reporting—think of it as a status page for your data. They will be a backbone we can use to surgically deploy monitors for data anomalies or breaking schema detectors where they make the most sense. They will provide a framework to encode dependencies for systems external to your data platform, we can even automatically detect that from query logs.
There’s much more on the horizon. We’re excited to be making significant progress on a direction we set out a little more than a year ago—A path towards a data platform that aligns data, value, and people. Naturally, we’re thrilled to witness how our customers will leverage Synq Data Products.
If you’re interested, we’d love to hear from you as we’re testing with the first group of selected customers. Get in touch with me at petr@synq.io.

.png)
.png)