Column-level lineage is out
We are excited to finally release column-level lineage to all our customers.
We have a major update to share with you this week - the release of Column-level lineage for all our customers! We are excited to hear your feedback and stories on how this new functionality has helped you in your everyday work.

Our main goal when developing this feature was to ensure clear visibility of column-level lineage coverage.
We understand the importance of having a complete picture of how your data is used and we want to make sure that all dependencies are presented to you so that you can make informed decisions.
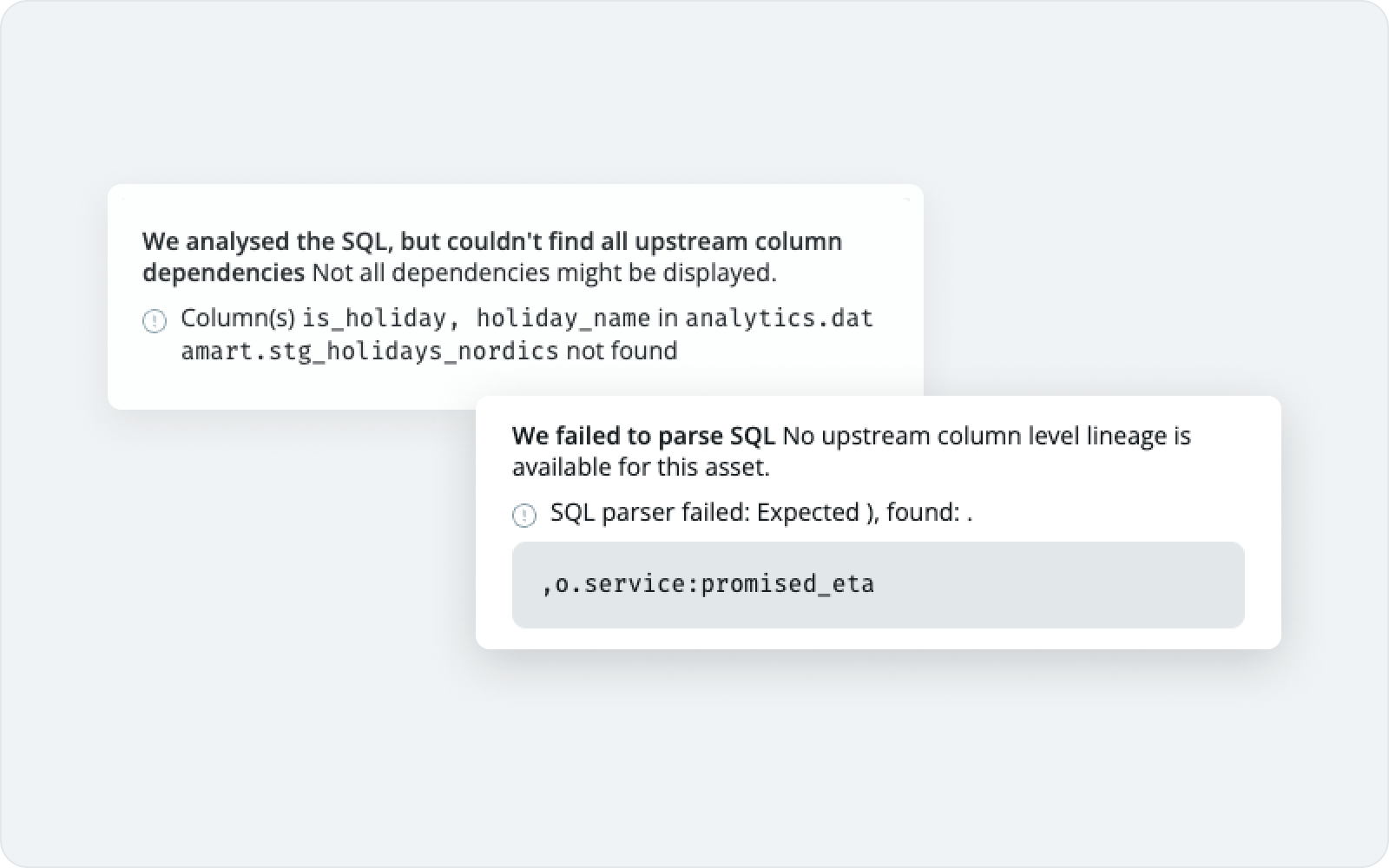
To achieve this, we have made it clear in the Code & Changes tab if there are any problems we encounter while analyzing the SQL. Additionally, when column-level lineage filtering is enabled, we show it on the lineage view, making it easier for you to navigate and inspect dependencies.
Column-level lineage final touches
This week, we made some final enhancements to our supported SQL constructs. We added support for TABLE(FLATTEN()) from Snowflake, which now enables us to support other special table functions present in Snowflake. Additionally, we improved how output column names are derived from expressions when no alias is used. We also spent some time improving the ordering of inferred columns to match the exact order present in the SQL. This way, the order of columns in CTEs and subselects using named, anonymous and wildcard columns is preserved. Finally, we extended our test suite to verify if columns inferred from SQL match those present in the DHW. Our test-suite was extended to verify if columns inferred from SQL match those present in the DHW.
Build with data you can depend on
Join the data teams delivering business-critical impact with SYNQ.