Delivering Reliable External Data Products with a Unified Observability Layer
How Shalion combined dbt tests with SYNQ anomaly monitors to proactively detect issues across hundreds of retail sites
Data at Shalion
Shalion is a global leader in eCommerce intelligence, working with brands such as Heineken, JDE, and Danone. Shalion’s platform unifies digital shelf and retail media insights, helping businesses make data-driven decisions. The solutions deliver product performance data from over 1,000 retailers across over 85 countries, offering full visibility into every aspect of the eCommerce performance.
Data is the product of Shalion and the key deliverables to customers are Looker Embedded dashboards and data sharing infrastructure where data is shared with customers daily.
“At Shalion, we lead the quest for data quality. Our persistence in delivering reliable, accurate data means you can trust every insight and make informed decisions that drive digital shelf excellence.” – Shalion’s commitment to customers
Key challenges
- Delivering reliable external-facing data products: A top company-wide risk is providing customers with wrong data – either through embedded Looker dashboards or through the data sharing infrastructure where data is shared with customers daily
- Proactively detecting issues across partners: Data is scraped across 1,000 retailers, each varying page type. It’s a must to be able to detect issues proactively, and as close to real-time as possible
Shalion has also bought into the Data Mesh concept and needed a central hub for operationalizing ownership of issues on data assets to relevant product squads, and systematically improving and monitoring the SLA of data products.
Data is our product. Our customers make decisions every day based on the insights we provide. The worst that can happen is if we deliver incorrect data to customers without us being the first to notice
Building reliable data products with a strong data governance layer
“This is not my first time building a data stack. Before joining Shalion, I knew I wanted a state-of-the-art data stack that could support the critical use cases of data we have,” says Alejo, Shalion’s Chief Data Officer. We decided on using Snowflake as the data warehouse with data modeling managed through dbt. Looker is used for internal and external-facing dashboards.
Providing customers with high-quality data is a company-wide priority and we decided on SYNQ for data observability and Select Star for data discoverability.
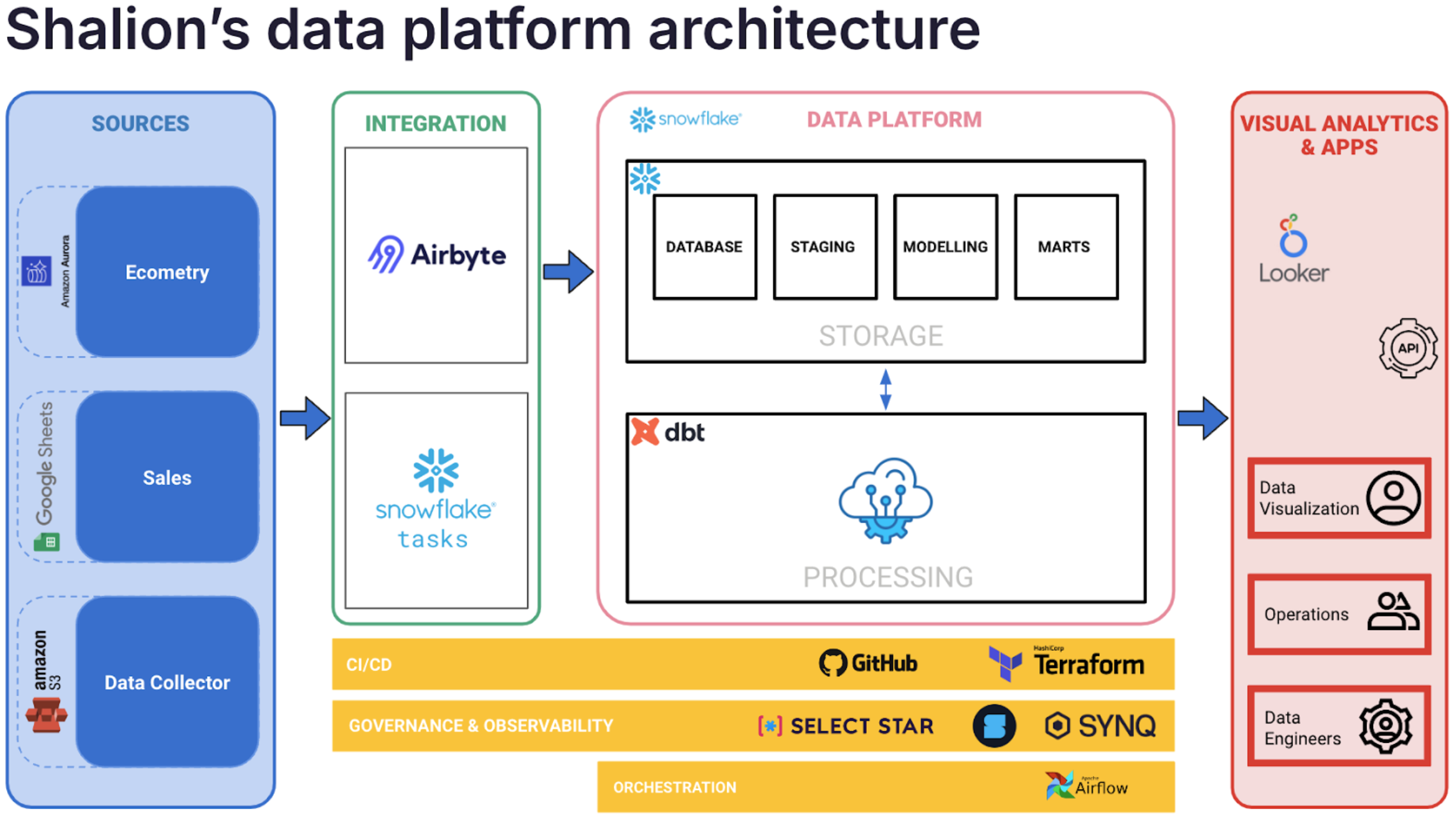
I originally thought we could cover our data observability needs with dbt and open-source observability tooling. However, I quickly realized that use cases get complex such as the ability to deploy monitors across many segments. We couldn’t do this with that type of tooling
Monitoring scraping data across 1,000+ partners
Shalion’s main data source is scraping data across 1,000+ retailers each retailer having 2-3 scraping templates resulting in over 2,000 unique templates. This data lands in S3 and has multiple preprocessing steps after that such as classifying categories, image-to-text processing, data filling, data filtering, and aggregation. The data team needed to know of issues as data landed in S3 and on the final marts exposed to customers.
The testing strategy was clear–focus on testing data heavily at the sources and final marts layers
- Sources – check the freshness and volume of data coming in with custom monitors running on each scraping partner
- Marts – ensure that data at the final layer is reliable, including bespoke rules for what makes up a unique scraping template key
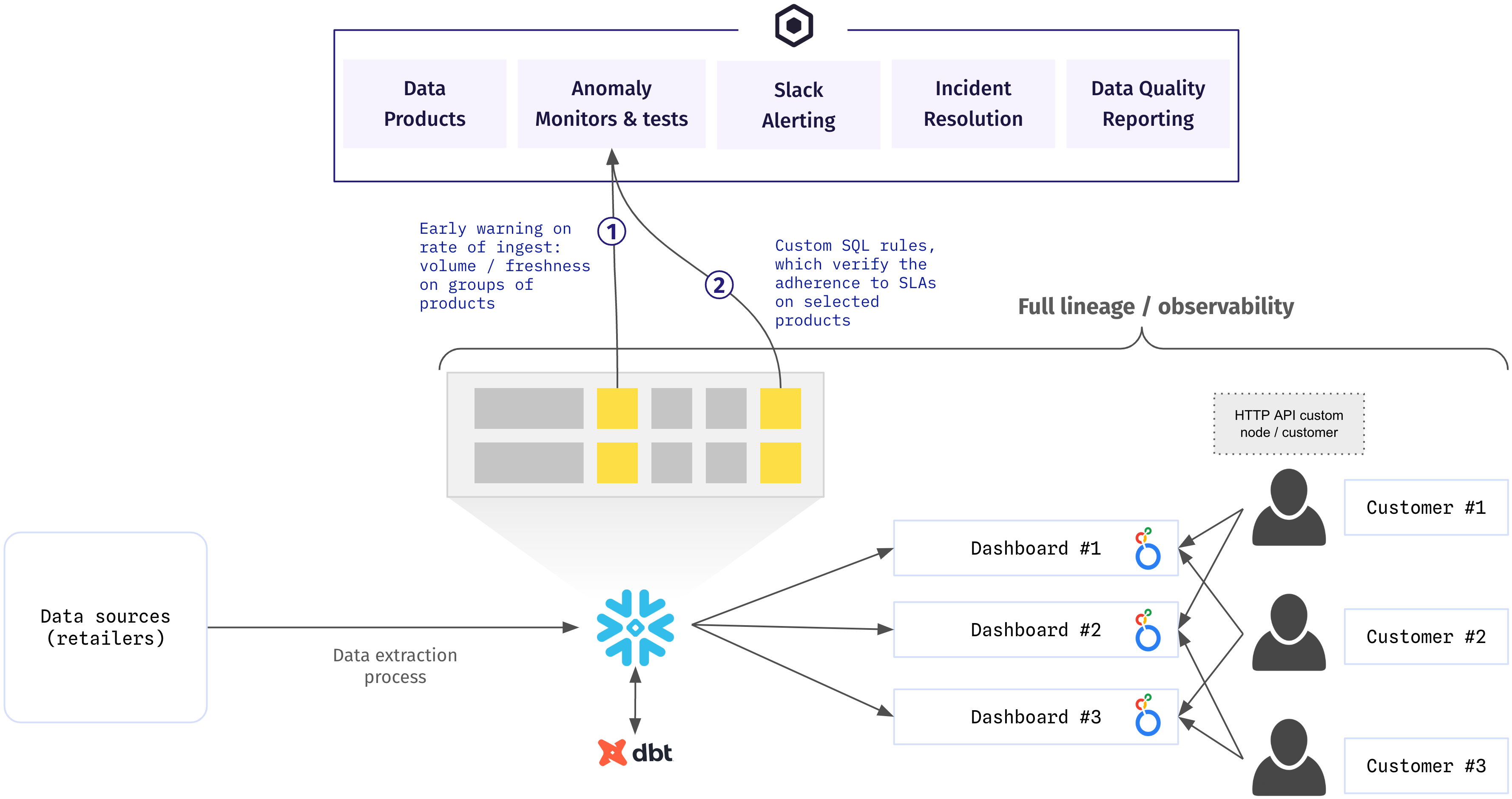
Shalion combines the best of both worlds with 250+ dbt tests checking for not_null, uniqueness, and more bespoke data verification tests. This is combined with 300+ SYNQ anomaly monitors, with some of them monitoring volume, ad-related metrics, and freshness for each key partner.
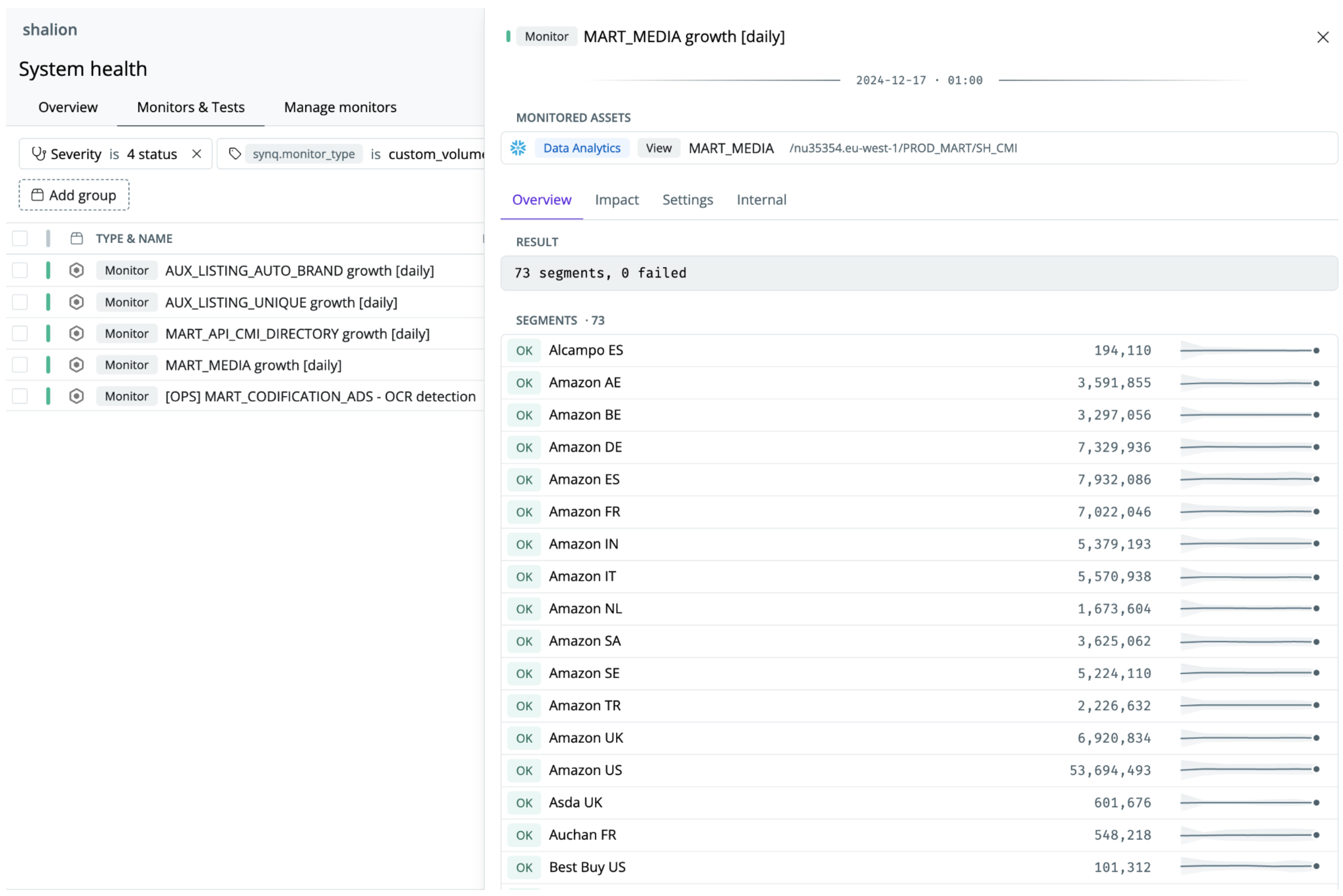
“Some of our retailers are much larger than others. Only by monitoring key statistics on a partner level can we detect issues that may not be visible in more aggregate metrics”
Delivering reliable data products using a data mesh approach
“We group our data products into source-oriented, aggregate, and consumer-oriented products. Each of them consists of several data products and hundreds of assets. With the data product overview, we know right away if we have any issues and where they fall,” says Alejo. If there are issues in the source-oriented products, the data team knows to notify the Ops team so they can go back and fix the scraping issue and customers may need to be notified. If the issue is on consumer-oriented products, customers may need to be notified.
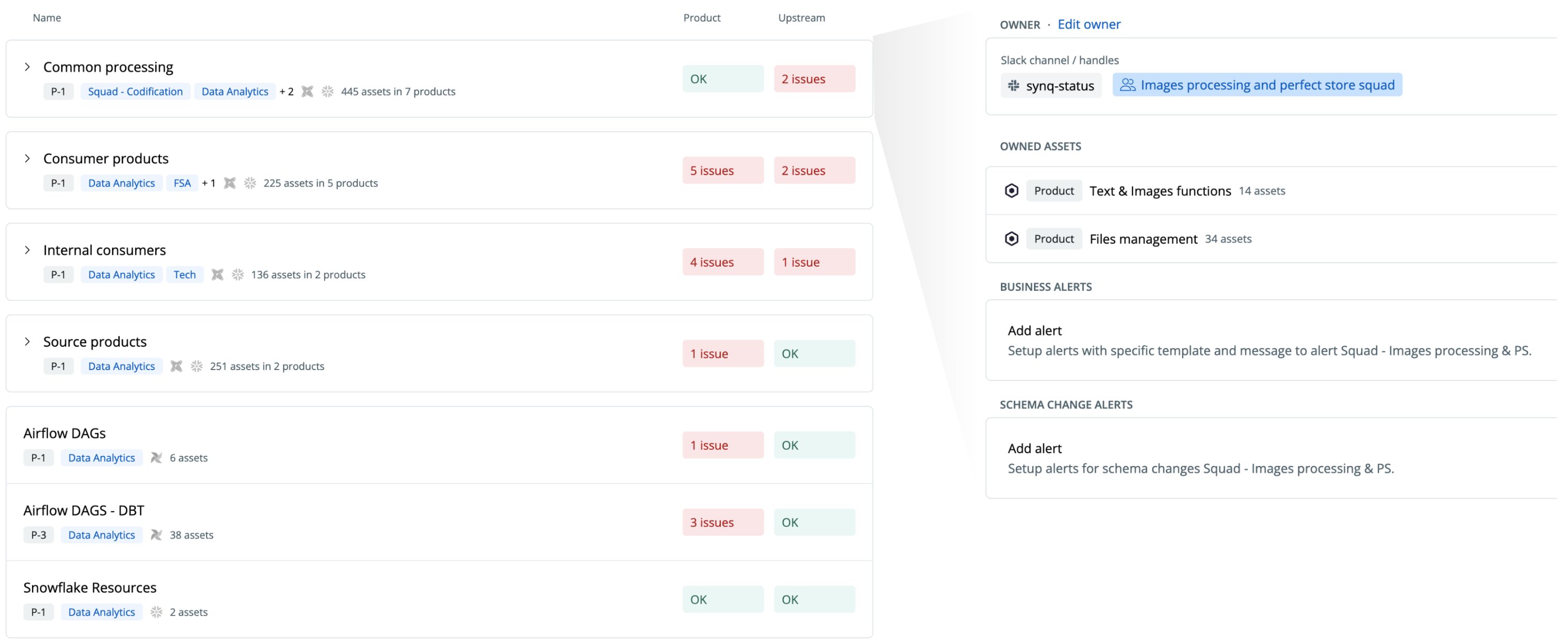
“As part of the data mesh, I’m also starting to get the rest of the organization bought in and have identified product squads who are owners of data products. I like to think about it as a RACI (responsibility assignment) matrix to separate accountability and responsibility. Accountability mostly falls on business and product – the person who has the most knowledge about that domain and product, and has the authority to define things such as metric definitions, quality policies, and privacy policies. The responsible sits on the data side, is hands-on, and can fix issues that occur.”
With SYNQ, we can operationalize our data mesh efforts–relevant product teams are automatically notified of issues on data products they own in Slack helping them take accountability for their quality
Measuring SLAs of data products
“I’m obsessed with us being able to monitor the quality of the data we deliver – from our ability to extract source data accurately to the accuracy of the data processing steps,” says Alejo.
To achieve this, Shalion is breaking down the monitoring of the data quality as follows
- Completeness – has all the data been extracted from retailers on a given day
- Processing performance – what’s the quality of our downstream processes? For example, out of 100 scraped products, what % can our classifier assign a category to
- Accuracy – how well are the data products performing? For example, what is the share of brand reported by Shalion in terms of ads and listings broken down by countries
“Next on my list is being able to deliver and commit to SLAs for data products towards our partners. The strength of our data quality combined with our ability to monitor it, will be a competitive advantage for us as a company”
Verdict: Impact of bringing on a data observability platform
“It’s been 6 months since we started our POC with SYNQ. Since then, we’ve seen significant impact,” says Alejo.
- Number of incidents – the number of data incidents has been reduced a lot. “When I joined there were several incidents per day. Now, it’s the other way around. We have weeks with only one or no incidents”
- MTTD (mean time to detect) – we have gone from having a reactive approach to being much more proactive. So now, we’re the ones to notify the Product and Customer Success teams before they notice there’s an issue
- MTTR (mean time to recover) – we previously spent 80% of the time working reactively on identifying the root cause. We’ve significantly reduced this by having everything in one place – from seeing error logs to being able to correlate events such as recent git commits with a specific issue
Every day, we review SYNQ incidents and assign ownership in our daily standup. We look through each open incident and go around the room asking, “Does this incident resonate with you?”. There’s a lot of correlation between ongoing issues and open PRs and merge requests, and this way of working saves us a lot of time
Want to learn more? Watch the webinar with Alejo, Shalion’s Chief Data Officer on using a data reliability platform alongside dbt.

Build with data you can depend on
Join the data teams delivering business-critical impact with SYNQ.