How we built code-column lineage


In my previous article, I explained why the power of SQL code impresses and scares me in equal measure. It has a lot to do with the limitations of data lineage. Even column-level lineage – an improvement on simple table-level lineage – doesn’t go far enough in helping data teams understand SQL logic and protect themselves from the potential adverse side effects of seemingly simple changes.
I ended that article by saying that, to tackle these issues, we decided to take Synq’s functionality to a whole new level. Here’s what I meant by that.
Tracing logic through the code
A powerful combo- lexer and parser is at the heart of nearly every parser designed for mainstream programming languages.
A lexer’s responsibility is to break the source code into tokens. It recognizes keywords (such as SELECT, FROM) and identifiers (dim_accounts, account_id). It feeds the tokens to the parser responsible for constructing the abstract syntax tree (AST) that represents the query.
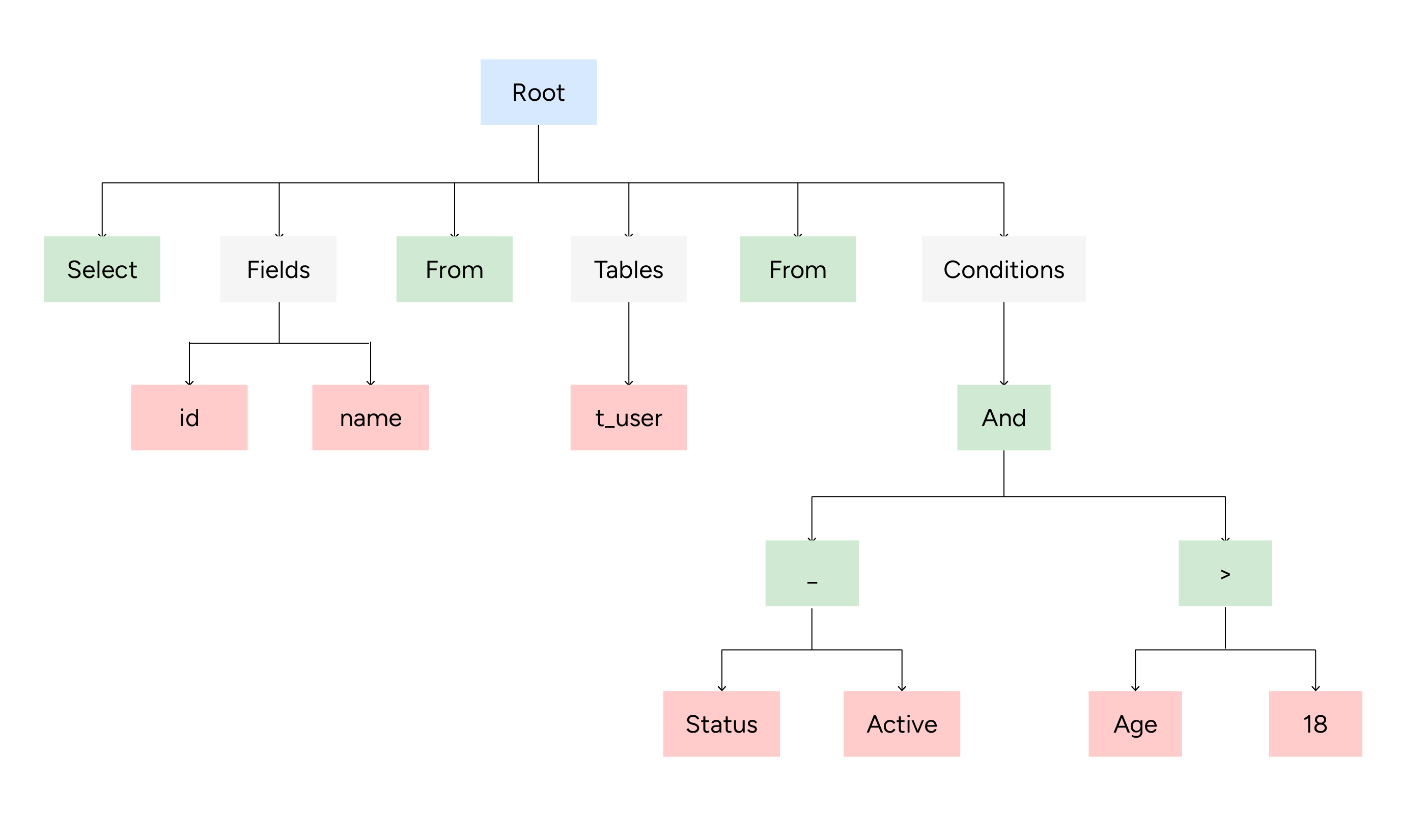
By traversing the produced tree, we can analyze the structure of the source code and extract meaningful properties.
Column-lineage parsers are built on this approach. The SQL code is lexed, parsed and traversed to trace the logic flow recursively and ultimately extract column-level dependencies.
However, AST representation creates opportunities for more advanced solutions than column-level lineage: we can trace the flow of logic within the file as well.
If the final column is selected from a CTE, selected from another CTE, and finally from the upstream table, all this logic flow can be extracted from the source code. This is what Synq does.
With excellent control of our lexer and parser, we can propagate token location through the entire system. (This control is why we don’t use parser generators in Synq.)
Let’s look at an example.
In one of the transformations in Synq, we extract a timestamp of commits from log-level data. This is done in multiple steps:
- Parse JSON payload and extract commit metadata
- Extract the Author object from the commit
- Extract createdAt timestamp from the author object
Technically, this is done as nested SQL queries, and logic is described in a couple of dozen lines of code. In larger codebases, such transformations could live alongside complex code with hundreds of lines.
With column-level lineage we are still left with no support to understand the SQL code itself.
But with column-code lineage Synq extracts the location of tokens and, therefore, precisely understands the flow of logic through SQL files.
To start, we can highlight the exact flow of logic and visually help guide data practitioners through the code:
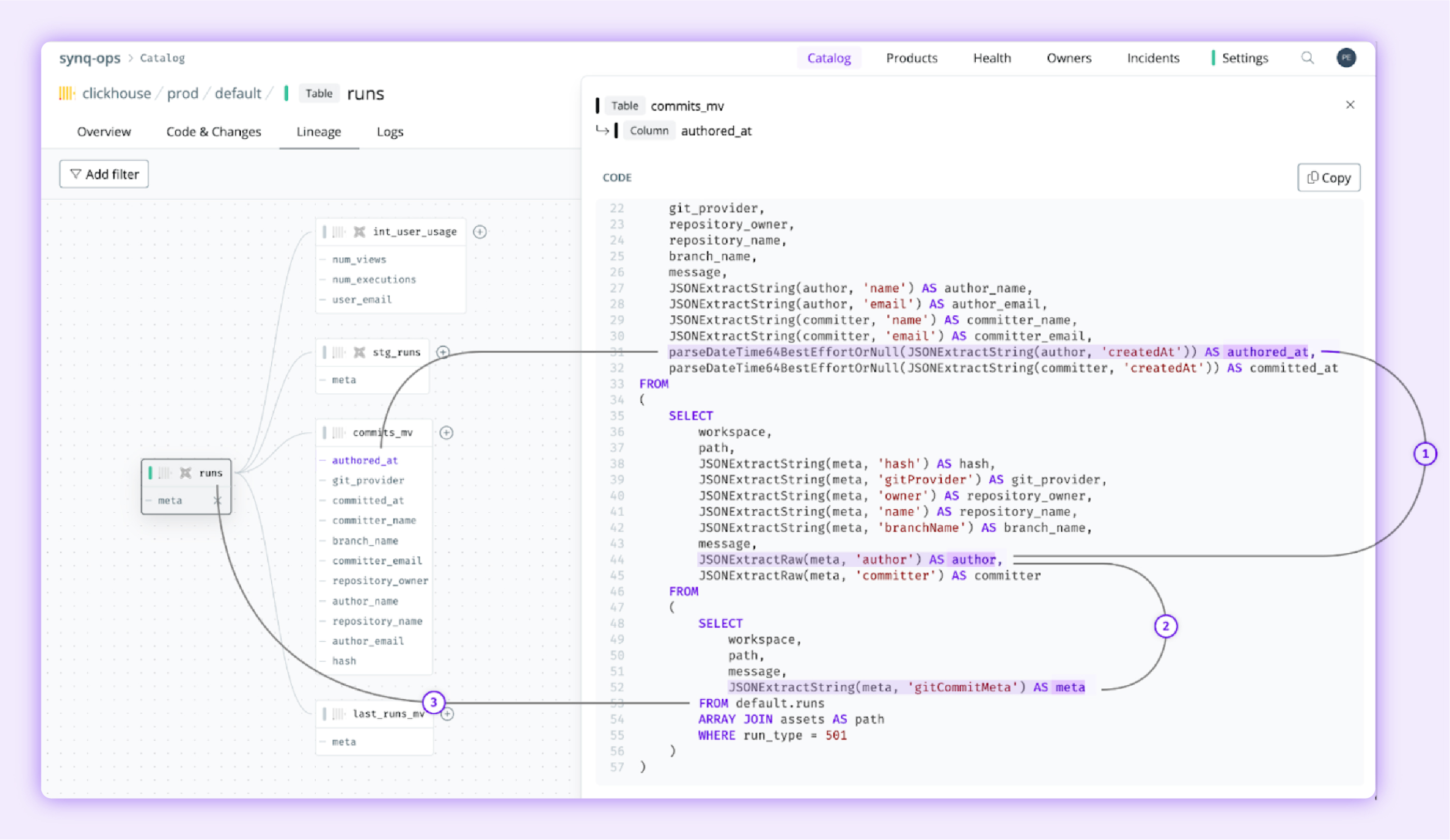
How Synq traces dependencies between CTEs, subqueries, tables and columns.
With Synq column-code lineage, we track dependencies across tables and columns and within the file across subqueries or CTEs to facilitate new, accurate and previously impossible refactoring and debugging workflows.
But that’s just the beginning.
The result: Software development-like experience
We started Synq with the mission to help close the gap between the tools available to data practitioners and software engineers.
Much software writing is commoditized: programming languages provide language servers that facilitate common workflows such as jumping to definition, seeing usage, renaming, etc. This is all powered by strong lexers, parsers, and semantic analyzers.
Synq’s column-code lineage opens a number of these workflows for data practitioners. Let’s look at three use cases:
- Go to definition — right-click the relevant token in your source code representing the column and jump to its definition. This brings you to the relevant CTE, where that code is defined with the appropriate parts of the code that execute the logic highlighted. This helps trace the logic flow to see how data is represented.
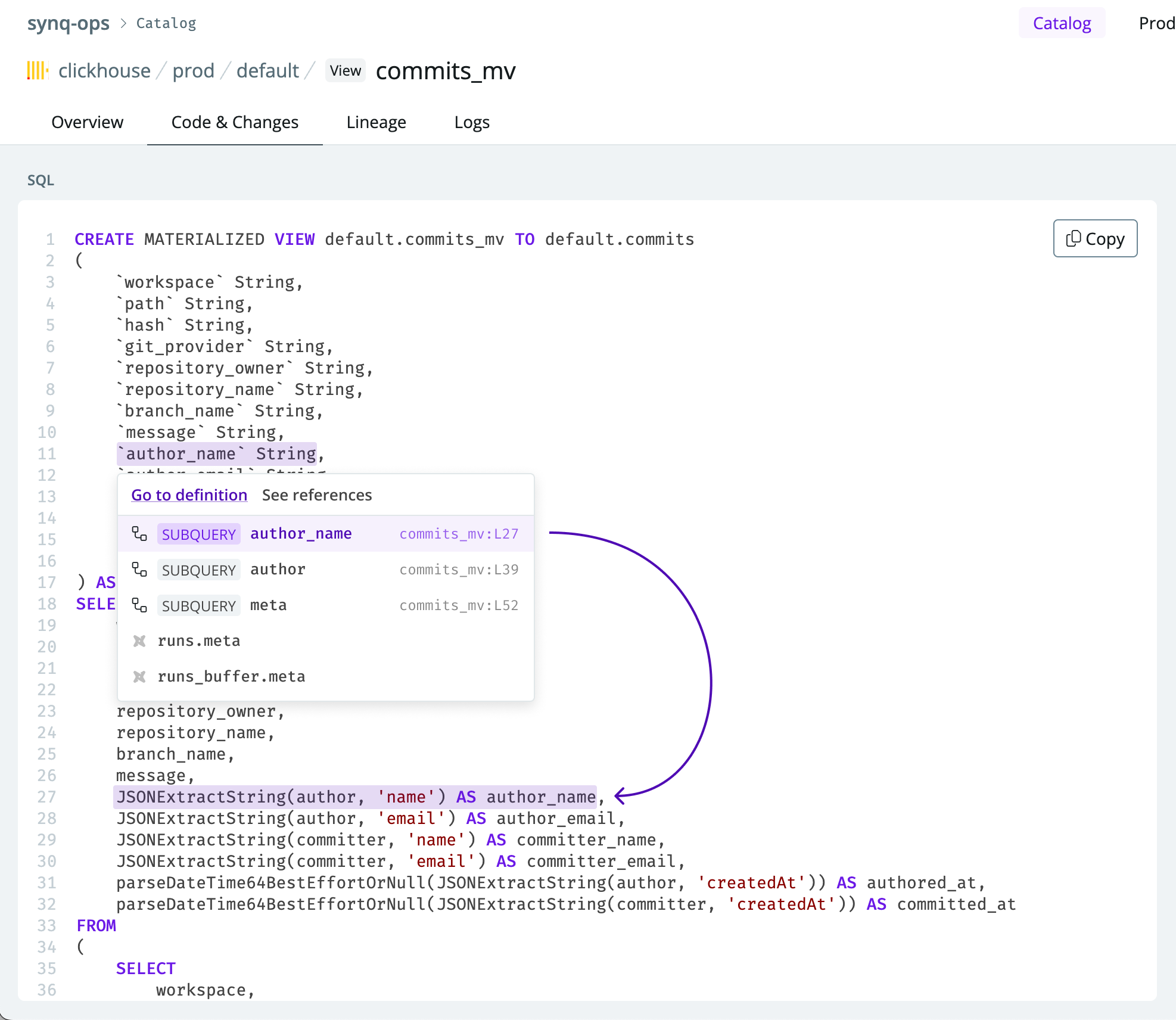
Jump to the relevant code with Synq code-column lineage.
- See usage — reversing the workflow, we can highlight a column within a CTE and see where it is being used in the file. It is pretty helpful to understand what impact a change would have!
- Understand the logic flow — aggregating this data from columns to CTEs and selects, we could derive a higher-level logic flow of the given SQL file—no need to break it into files or scatter it across notebooks. The information can be parsed from the SQL.
With a rich representation of SQL code structure that ties together tables, columns, lines of code, and the exact location of tokens in the file, we are just scratching the surface of what is possible and what new workflows we can create for data practitioners.
This is one of the ways Synq is closing the gap between the data practitioner’s toolkit and the software engineer’s toolkit.
We’re excited to see the fast adoption of our column-code lineage across all our customers. If you’re a data practitioner like me, you’ll appreciate how it makes changes in complex SQL code a little less scary.
Drop us a note to see this new concept in action.


