The importance of data quality for automated customer engagement

Data-driven incentives can be incredibly effective in getting your customers to go from a free trial to the paid version or to come back and buy that item they left in the checkout cart with a timely placed 5% discount.
Nudging: According to Thaler and Sunstein, a nudge is any aspect of the choice architecture that alters people’s behavior in a predictable way without forbidding any options or significantly changing their economic incentives. To count as a mere nudge, the intervention must be easy and cheap to avoid.
Top companies build a deep understanding of how dropoffs and conversions work across different cohorts of users and engage users at the right time to encourage behavior that pushes them toward a desired action.
But the effectiveness of this type of customer engagement is only as good as the quality of the data that goes into it.
In this post, we’ll look into
- The benefits of using data for nudging your users throughout their lifecycle
- How data quality issues impact the ROI of automated marketing
- Steps you can take to avoid costly issues on marketing pipelines
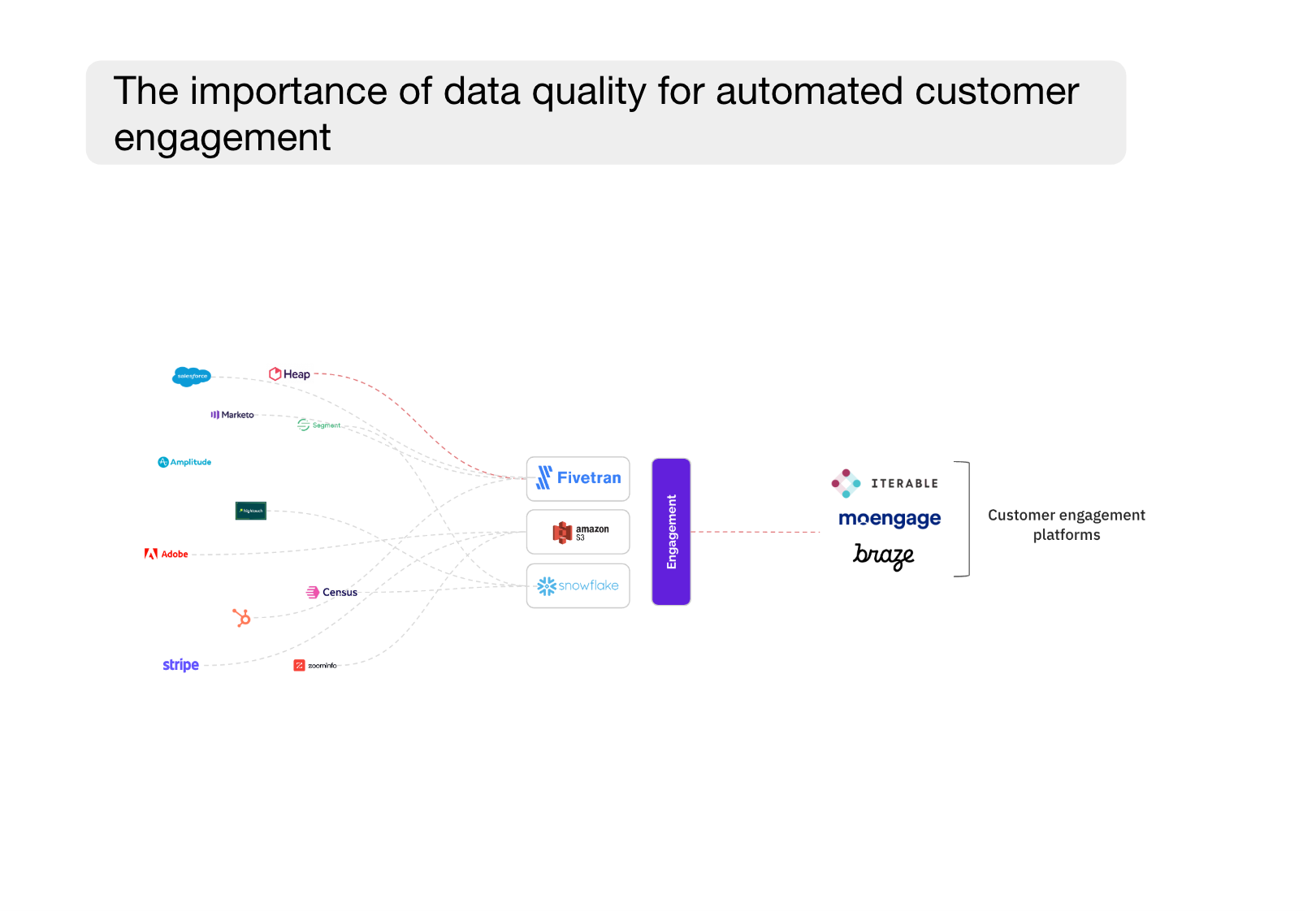
The effectiveness of using data when engaging customers
In order to engage your customers at the right time and with the right message you first must be able to understand their behaviour. This can include understanding how they’ve been using your product, what other products they’ve looked at, and what their demographics are.
Signs that it can be a good time to nudge a customer could be
- An eCommerce high-value customer leaves your website after inputting their email with items still left in their basket (data source: Shopify)
- A B2B user on a free plan starts to invite team members to your platform (data source: Amplitude)
- A user from a highly valuable domain signs up for your newsletter (data source: Clearbit)
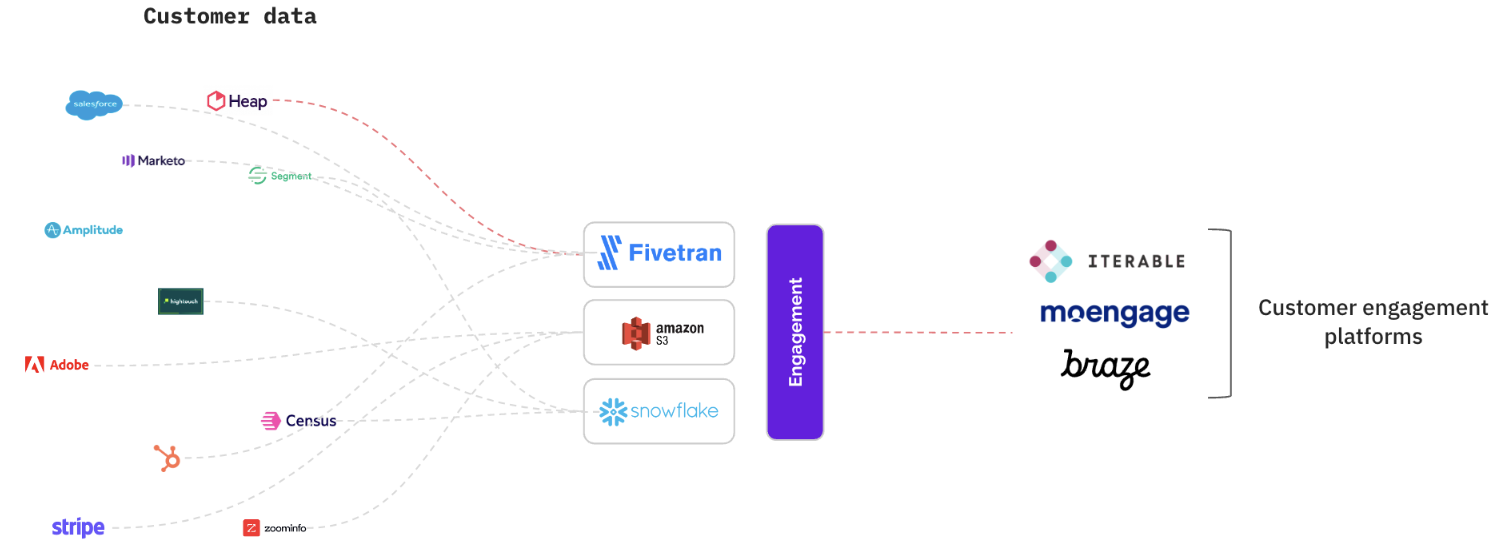
To maximise the return of your campaigns, you should constantly keep an eye on your conversion rates and run well timed A/B tests to be able to isolate the effect of the nudge relative to other factors such as seasonal trends or a change in user behaviour.
The hidden cost of data issues on marketing pipelines
If you’re using data to programmatically allocate your ad spend to platforms such as Meta and Google, incorrect data may lead to a direct loss on return on ad spend. But automated customer engagement such as emails and in-app notifications are practically free to send and the cost is instead seen through a lower ROI on your customer engagement efforts.
For example,
- Sending a customer who abandoned their basket a 5% discount code on average yields a 2% conversion rate corresponding to a $5 profit per customer
- But an issue in the Segment integration that emits events from your website to your data warehouse used to send email campaigns in Iterable means users on iOS are not sent emails for a full week
It’s not uncommon for customer engagement platforms to read from dozens of sources and rely on hundreds of data transformations from your data warehouse. Emails and notifications are sent in real-time, often targeting hundreds of thousands of users each month. At this scale, it’s practically impossible to manually monitor if you’re suffering from faulty upstream data that’s causing you to send inaccurate notifications.
“We were sending in-app notifications based on stale data for weeks before we noticed it. Not only did we miss out on opportunities to engage customers at the right time but we also increased the likelihood that they become ad-blind from seeing irrelevant notifications” - Marketing specialist at 1,000 people scaleup
Building reliable marketing data pipelines with Synq
To give you a 360 overview of your marketing pipelines and proactively detect errors that impact your customer engagement initiatives, Synq offers an all-in-one solution that combines your existing tests and self-learning anomaly monitoring.
Synq adapts to the seasonality of your business, incorporates your feedback, and delivers actionable predictions. Monitors run every 30 minutes, encompassing all data used for automated customer engagement, and automatically infer the relevant sources to monitor so you don’t have to allocate dedicated data engineering time.
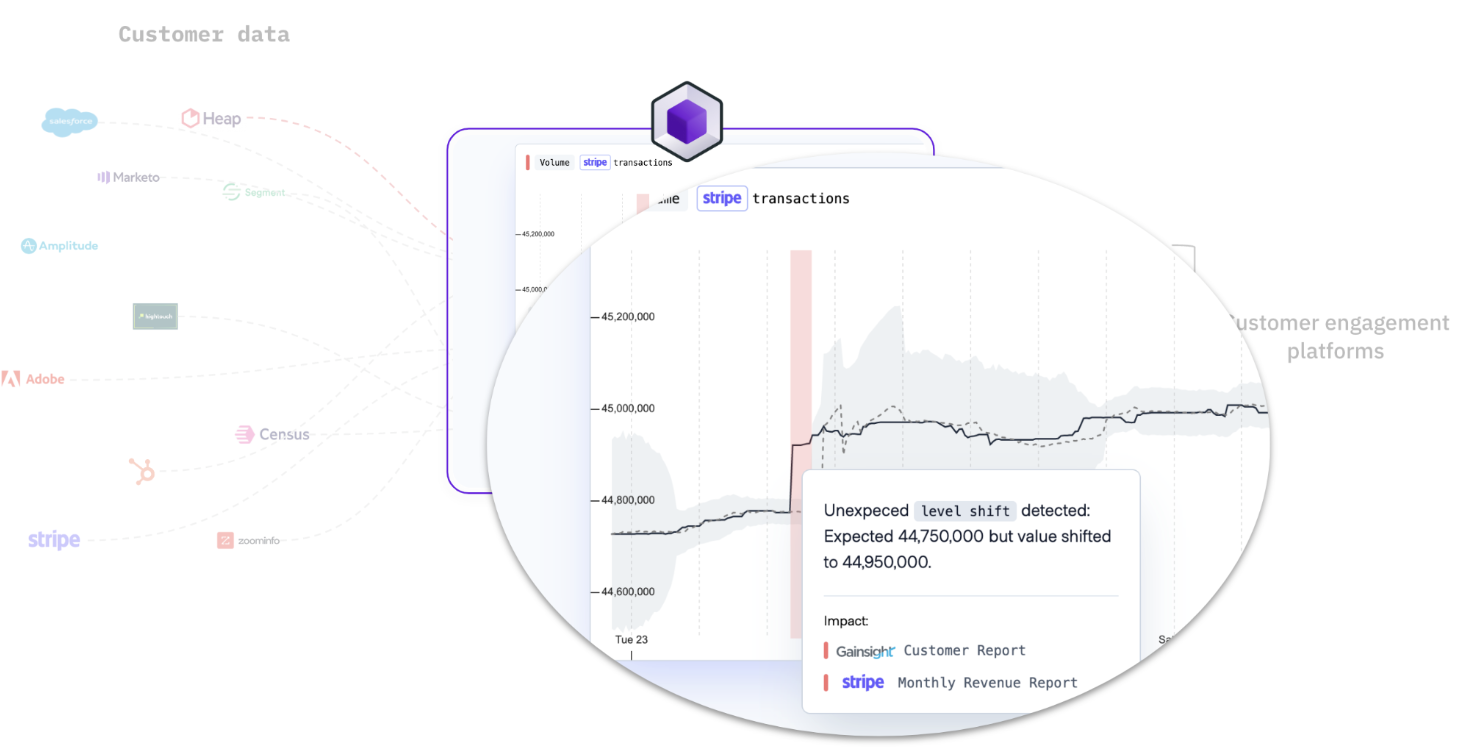
Synq highlighting a sudden jump in the volume of Stripe data through automated anomaly monitoring
Achieving a 360 overview with Synq: With less than 30 minutes of setup time, Synq automatically infers your data landscape, integrates existing logical tests, and activates ownership across engineering, analytics, and BI teams. Relevant business stakeholders can also be notified of any affected areas.
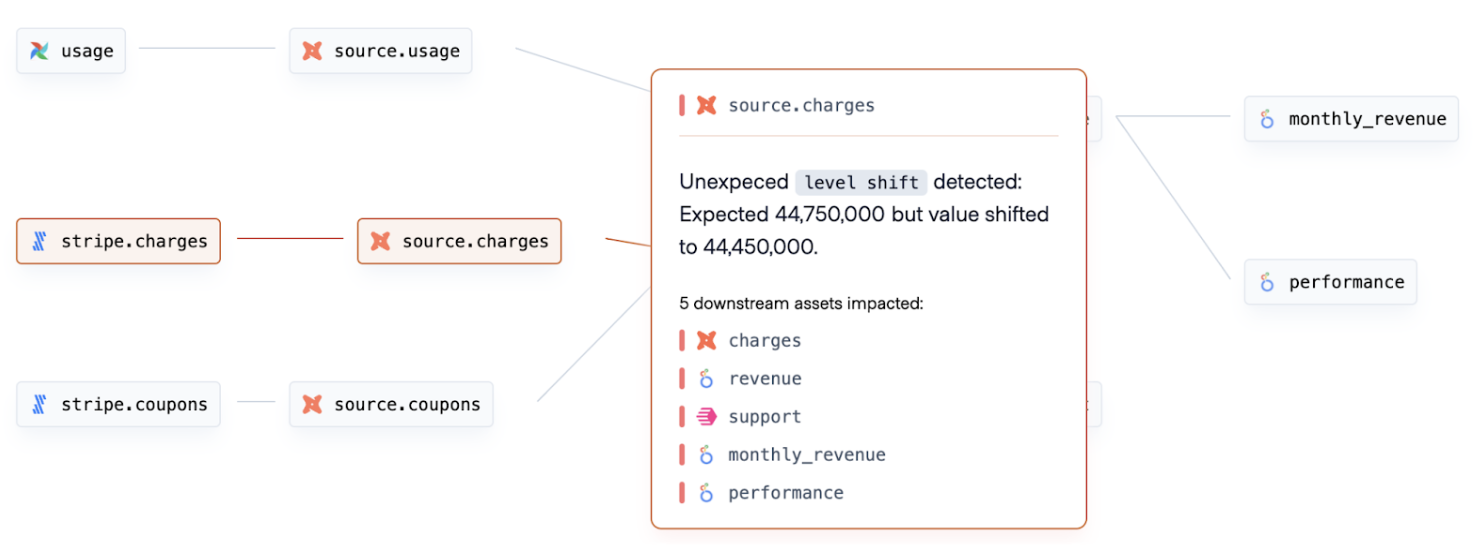
Synq automatically infers a 360-degree overview of your data
About Synq
Synq is a data observability platform trusted by forward-thinking teams. We work with top companies like Typeform, Cazoo, and Intstabee to build reliable data where it matters most.
Testimonial:
“Synq plays a big part in reducing overhead for us in managing the complexity across our existing stack. Despite the complexity of our setup we were up and running without any custom engineering work” - Head of Analytics, Cazoo
If you want to learn more about how Synq can help build reliable marketing data pipelines, we’d love to speak with you. Reach out to mikkel@synq.io.

.png)
.png)