Defining ownership and making it actionable


We’ve been speaking to 300 data teams, and the most common topic? Ownership. This is not surprising. Upwards of 50% of data issues can be traced back to issues upstream that the data team has little control over. At the same time, larger data teams now consist of hundreds of people and thousands of data assets - way more than can be in one person’s head.
Too often, we’ve seen ownership initiatives fail to have much impact. They often start with good intentions but end up as one-off exercises that are not maintained or put into action.
Actionable ownership is about finding the right balance between what will have a material impact from day one, letting you get started without needing an upfront organisational change and fitting into existing workflows.
In this article, we’ll walk through:
- Things to consider when defining ownership
- Making ownership actionable
- Managing upstream and downstream ownership
- How to get started
Things to consider when defining ownership
Well defined ownership creates clear boundaries within the data stack. It tells you who to go to if you have a question about a data set, who’s responsible for monitoring and acting on issues and who should be informed if the data they use is no longer reliable.
Ownership should span across the stack
The end product of data can rarely be limited to one chain in the stack. It’s almost always a constellation of upstream data sources, data transformations and end-user destinations such as dashboards. Data reliability is only as strong as the weakest link in this chain. Therefore, ownership should be managed across the stack.
Data reliability = lowest(upstream data quality, data model quality, dashboard quality)
In the example below, the reliability of the dashboard is low despite any well-intentioned efforts made upstream.
- Rigorous logging of calls in the CRM (sales ops) = high →
- dbt models with high test coverage (analytics engineer) = high →
- Unresolved errors in the LookML code of a dashboard (sales analyst) = low
It’s not always practical to bring out ownership to upstream and downstream teams who sit outside of data. But you can define ownership at the edges of the data modelling layer. Sources should define which teams upstream own them, and your most downstream mart layer should indicate which teams are using the models downstream.
Be systematic when setting ownership
Too often, ownership ends up as a static page in Notion. This rarely works well. Teams reshuffle, new teams are formed, and people leave and join.
- Ownership should be actively managed. An example of this is using the dbt meta owner tag for setting ownership and enforcing that new data models have an owner set through CI checks
- Use groups that already exist in your company, such as Google Groups formed around existing teams. These will always be up-to-date as people leave or join without you having to manage groups for data ownership specifically
Start by setting ownership for your most important data
While you may not want to set ownership for all your data assets, we recommend you at least do it for important data. Having assets with clear ownership makes it more likely that the right people act on issues or are notified if the data they use is wrong. You can use two parameters to assess if data is critical
- Critical use case: Does the data have a business-critical use case
- Downstream impact: How many assets are downstream You should also consider setting ownership on data assets on the critical path (any asset that sits upstream of business-critical data is on the critical path). You can read more about that in the Designing severity levels for data issues guide.
Ownership should be set at the right level
Set ownership at the right level to make sure people feel accountable for the data they own.
- Set ownership at a too-high level and you risk that no individuals take responsibility. For example, by defining the owner as “@data-team” you risk the definition is too broad to act on.
- Setting ownership on an individual level creates a lot of accountability but little scalability. You run the risk that people move around to different teams, go on holidays or leave the company.
The right level to set ownership depends on your company structure and whether you work in an embedded or centralised environment. As a rule of thumb, owner groups should be smaller than 10 people and persist for at least 6 months.
Designing ownership for embedded teams
In embedded teams, there’s no shortage of ways you could define ownership.
- Individuals (e.g. Jane): We always advise against setting ownership on an individual as it’s inflexible if a person moves around, leaves, or goes on holiday. Accountability is high, but flexibility is low
- Squad (e.g. operations - self-serve): A squad typically has 1-2 data people. Setting ownership at this level is more robust to people moving around, but these groups are often too narrow and create key person risk. Accountability is high, but flexibility is low
- Collective (e.g. operations): A collective consists of multiple squads who work within the same domain. It’s typically small enough that data people still have context on what other squads are doing and large enough that multiple people can cover for each other. Accountability is high, and flexibility is high
- Discipline (data): The entire data team consists of everyone in data. You will likely never run into situations where everyone is on holiday but people won’t have enough context to comfortably cover for collectives outside of their own. Accountability is low, but flexibility is high

As a rule of thumb, we recommend setting ownership at the collective level. It’s both flexible enough that people can move around and cover when someone is on holiday and narrow enough that people have context and feel accountable.
For larger teams (50+), we’ve seen constellations of collective + squad work well. For example, a Slack alert about a test error on a model owned by the self-serve squad, could be sent to the #operations-data channel and automatically tagging @self-service-data.
For smaller teams (<10), we’ve seen constellations of discipline + collective work well. For example, a slack alert about a test error owned by the operations collective could be sent to the #data channel and automatically tag @operations-data.
Designing ownership for centralised teams
It’s simpler to define ownership for centralised teams. You likely already have a set of data assets you know are “core” or “critical” with many downstream dependencies. These are most often the assets that should be owned centrally.

A good starting point is to draw a diagram and count the number of downstream dependencies, and you’ll know which models are most core. You may also have certain data models with few dependencies that are still business-critical. See the Designing severity levels for data issues guide for more on this.
A common pitfall is assigning too many data models to a centralised team. This erodes the purpose of ownership. Instead, you should keep the number of assets owned centrally small and have higher expectations for them.
Making ownership actionable
The most common error we see data teams make is that they invest in ownership but forget to act based on it and therefore see little impact.
Be explicit about what’s expected of owners
Being an owner can mean many things to different people, so be explicit about what it means in your company. For example, being an owner of a data asset may entail
- Responsibility for monitoring issues and commuting them to downstream users
- Being the go-to-person for questions about the data asset
- Being responsible for evolving and maintaining the data asset Write this down and make it part of the onboarding process for new hires.
Delete unused data assets to make ownership manageable
Being the owner of a data asset comes with a tax. You not only ship a data model or a dashboard but also commit to ongoing maintenance. This should be factored into your strategy for how many data assets should be owned by each team or person.
If you’re serious about ownership, you can’t expect teams to continue to own more data assets and maintain the same quality. There may come a point where you want to do a “one-in, one-out policy” and continuously monitor your data stack for unused data assets. This could be a data model that no longer has any downstream users or a dashboard that can safely be deleted.

If the number of data assets owned by a single team grows to many hundreds, it’s a good time to look back and see which could be deleted.
Integrate ownership into your existing workflows
Build ownership into existing workflows to prevent it from becoming an afterthought
- Alerting: Integrate ownership in your alerts. Automatically route issues to the right owner or tag them in a Slack channel to bring it to their attention
- Metadata: Combine metadata with ownership to understand how well different teams take care of their data. For example, track uptime or test coverage for key data models by displaying the number of unused dashboards that could be deleted per team
- CI/CD: Enforce assigning owners when new assets are created. For example, use pre-commit-dbt to enforce that dbt models have an owner tag
Managing upstream and downstream ownership
Data teams we speak with can typically trace upwards of 50% of data issues back to upstream sources that the data team has little control over. They also have downstream data consumers discovering data issues as the top thing that causes them to lose trust in data.
Setting upstream and downstream ownership can help with both.

Managing ownership for upstream data producers
Upstream ownership is twofold: 1) If you work in the data team, how do you know who to go to upstream and 2) how do you create a culture where upstream producers take ownership of the reliability for data coming from systems they own?
Upstream teams can, by and large, be grouped into other data teams, engineering teams and non-engineering teams. Here are common ways for how to define and action ownership for each group.
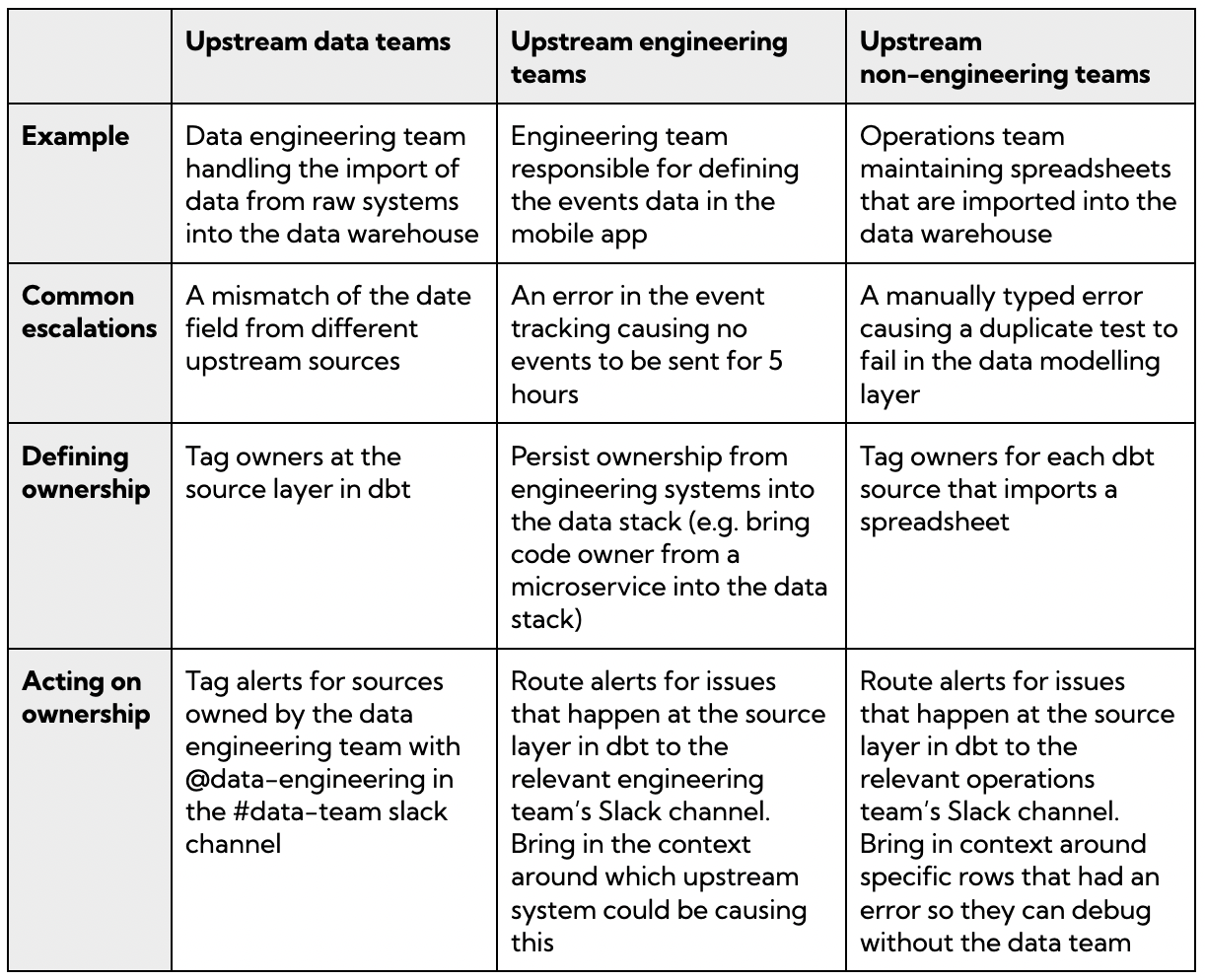
Managing ownership for downstream data consumers
Unlike upstream producers, downstream consumers are often not responsible for the root cause of issues but should be notified, so they’re aware and don’t make decisions based on faulty data.
Downstream consumers can, by and large, be grouped into data product consumers and other data teams. Here are common ways for how to define and action ownership for each one.

How to get started with ownership

- Start small. If you’re just getting started, you don’t have to define owners for all your data assets. Instead, start by defining the smallest possible amount of data assets that are most critical for your business
- Be consistent: Be consistent in how you define ownership and at what level so different teams don’t make their own interpretations
- Integrate ownership into your workflow. Use existing groups to define ownership that already represents how your company works and automatically bring ownership into your alerting workflow
- Don’t overthink it: Avoid making this a month-long project. Instead, get started by defining ownership for the most important assets and get some quick wins. Consider making a rule that for new data assets, at least the important ones should have owners defined when they’re created
If you’ve done this well, you should find yourself in a position where ownership helps you save time, get more reliable data and have fewer issues that are caught by end-users.

.png)
.png)