Untaming the spaghetti lineage

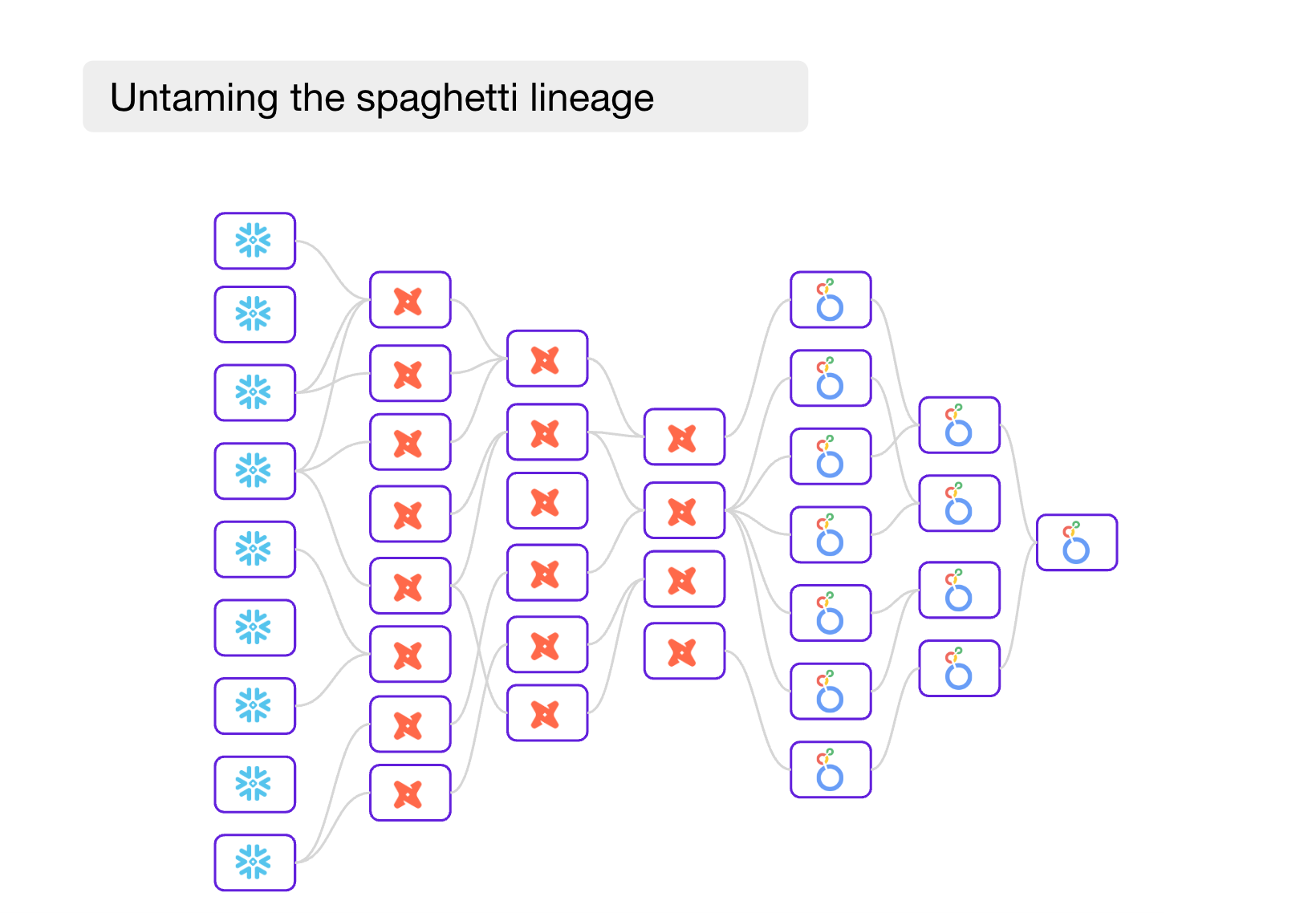
Lineage across the data stack is consistently top on the wishlist for data teams. As the data stack grows to hundreds of tables, data models and dashboards, the number of connections grows tenfold. It’s no longer possible to keep a mental map of how everything is connected in your head.
A good lineage can help you with this and accelerate core workflows such as
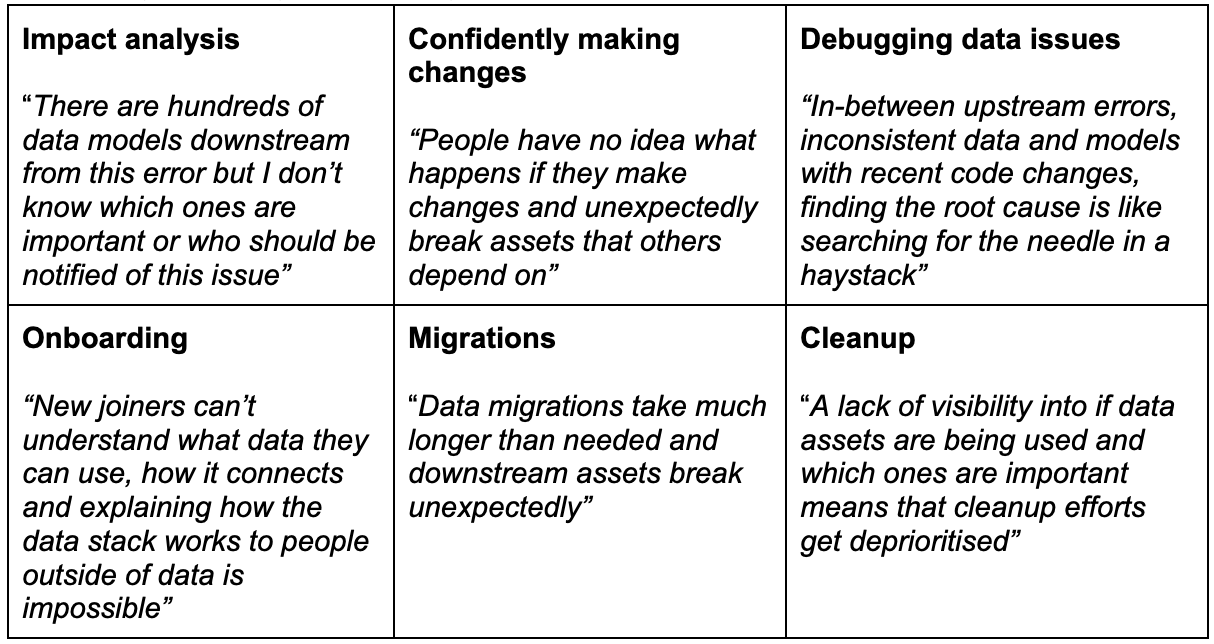
- Impact analysis – know if an issue should be treated with urgency based on the downstream impact and which stakeholders to notify
- Confidently make changes – understand the full downstream implications
- Debug data issues – trace back issues upstream to narrow in the investigation
- Onboard new team members – visualise dependencies to new joiners who don’t know all the systems
- Data migrations – migrate to a new data warehouse or tool by knowing the impact of changing a table definition
- Clean up unused assets – understand which data models, columns or dashboards can be deleted by knowing what their usage and dependencies are
Lineage breaks with scale
It’s common to hear from data teams that the lineage becomes unusable once they reach scale.
“Our lineage is like a spaghetti mess and it’s impossible to navigate it” - Analytics engineer in 20 person data team
Typically a few things start to happen
There are too many dependencies – when you’re about to update a field and see that there are potentially hundreds of data models that may be impacted downstream, it’s hard to know which ones are business-critical and who should be consulted first.
The lineage doesn’t span the entire stack – if you only have visibility into some systems it gives a false sense of security. For example, you may think that you know the full implication of changing a column definition but miss that it impacts the board-level KPI dashboard. Manually maintaining hundreds of exposures in dbt is time consuming and can be practically impossible.
The lineage is slow to load or doesn’t load at all – if you try loading a lineage on your screen with thousands of nodes you have to wait ten minutes for it to load, if it loads at all.
New joiners struggle to get up to speed – they don’t know the systems well and are more dependent on the lineage to understand impact assessment and ease the debugging workflow.
“In one larger UK fintech, each new joiner is put on the data floater rota after their onboarding is complete. With 3,000 data models you often have little context about where the data is used and it’s not uncommon that there are thousands of models downstream from an issue. Without the hard-learned experience of encoding what’s important in your head, new joiners have no way of identifying if an issue means they should drop everything and find the right owner to fix it, or if it should be added to the backlog instead”
Concepts we lean on at Synq to make lineage useful at scale
While there’s no silver bullet to making lineage useful at scale, we’ve worked with dozens of scaling data teams, some with tens of thousands of data assets, to address this.
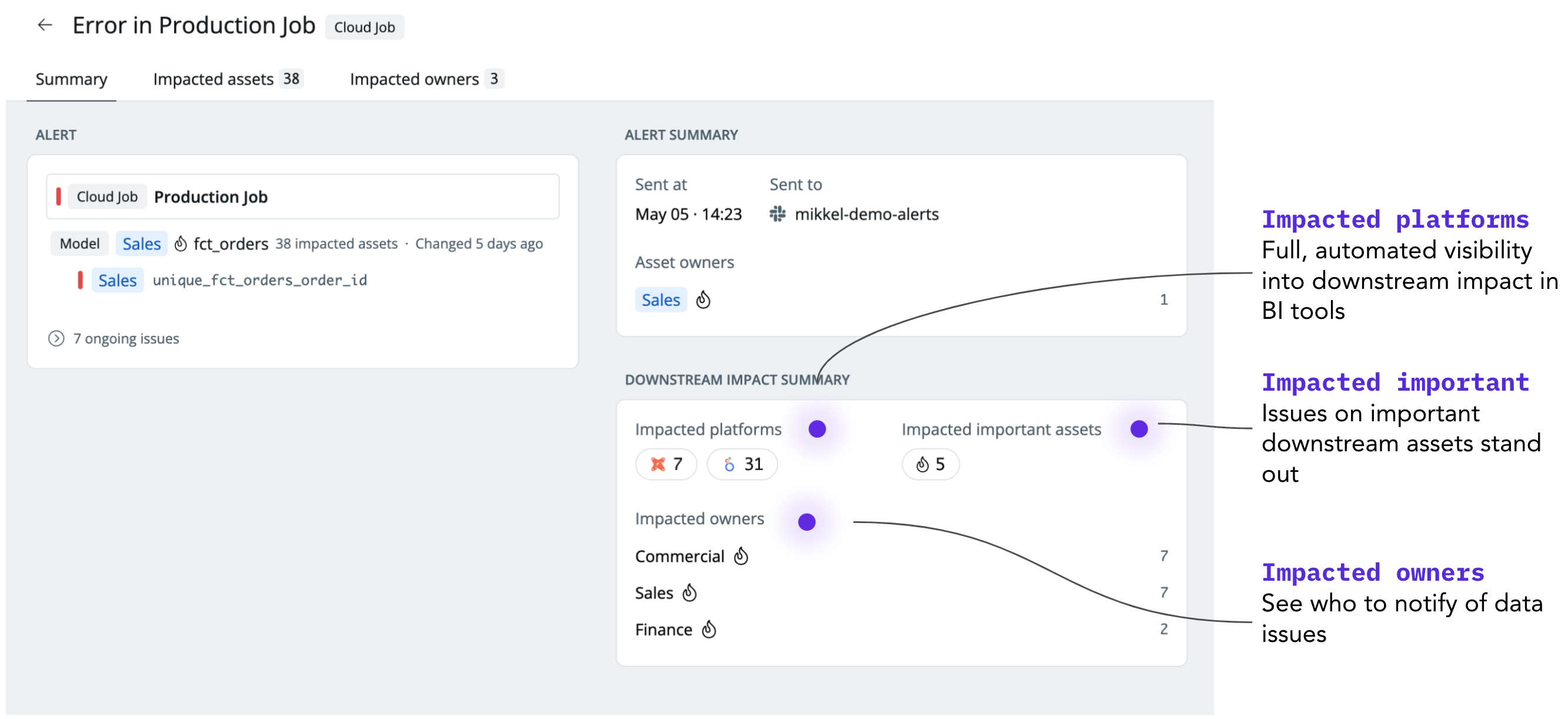
Assess the impact of issues fast and with confidence
Sometimes the best lineage doesn’t look at all like the lineage as you may know it. If you’re in the middle of resolving a data issue you often want to be able to answer these questions as fast as possible
- What’s the full impact of the issue across all my platforms
- Are any of my business-critical data models or dashboards impacted
- Who is impacted and who should potentially be notified
In Synq, we display a summary that helps you answer these questions without showing a map with nodes and links.
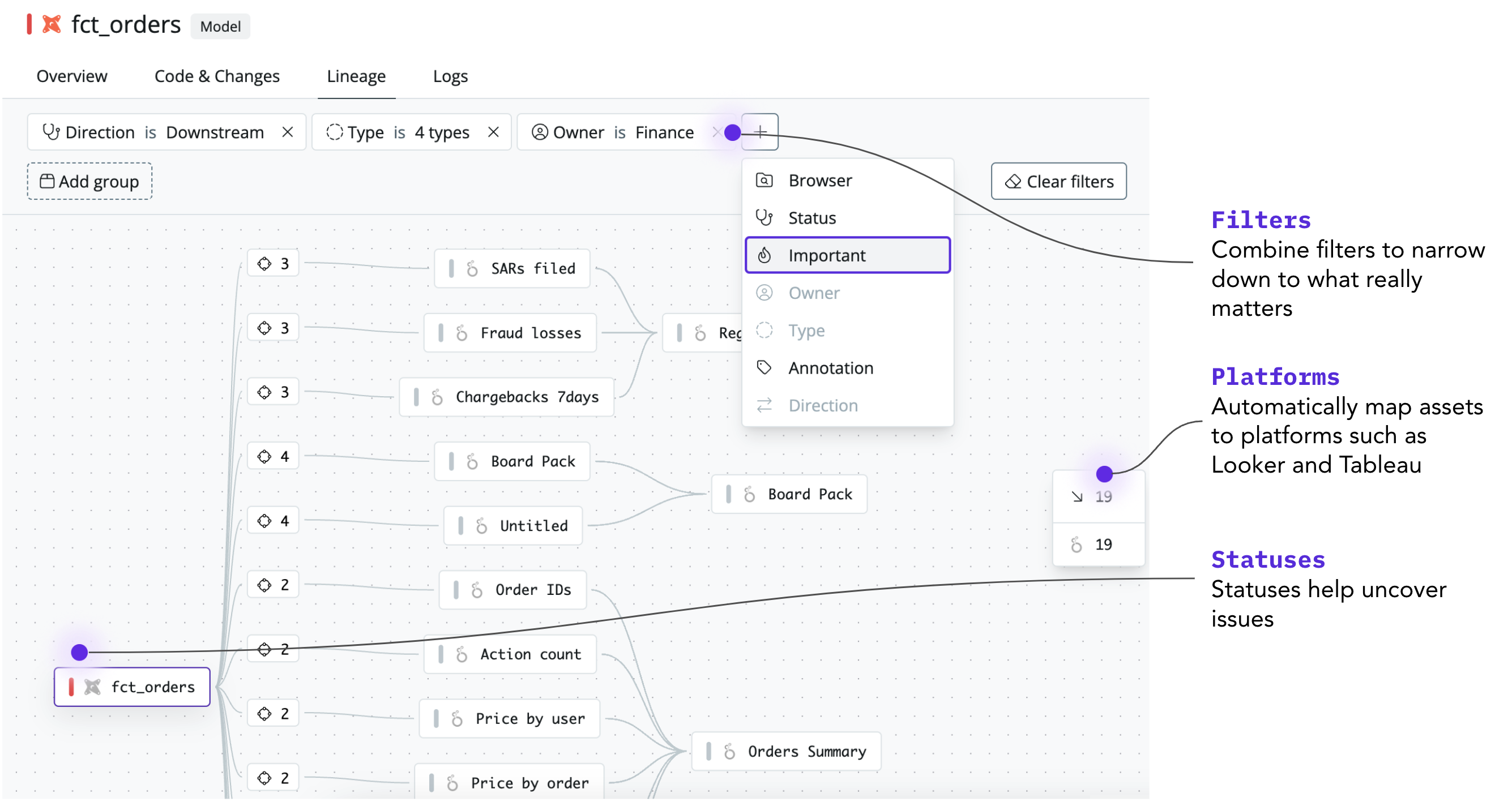
Confidently make changes and debug issues
Whether you’re in the midst of a migration, want to refactor a data model to make it easier to use or are removing unnecessary dashboards, lineage with the right level of detail can help.
“If you want to find a good coffee place when you’re visiting a new city, you may open Google Maps, search for the city, zoom in on the area you’re staying in, find the highest rated coffee shops and narrow down to those that are open at 7am and have free WiFi. In order for a lineage with thousands of nodes to be useful, it should resemble this experience”
For example, in Synq you can
- Apply filters such as owner and importance to help narrow in on who may be impacted, and how cautious you should be before making a change
- Automatically see platforms such as Looker and Tableau to help you understand the full downstream impact before making a change
- See statuses of data assets to spot issues and potential bottlenecks
Making lineage useful for new joiners requires a fundamental shift
Taming a spaghetti mess with thousands of interconnected dependencies requires a fundamental change. With dbt 1.5, dbt has focused on becoming more usable for larger deployments with better multi project support, groups and access controls.
“Choose which models ought to be “private” (implementation details, handling complexity within one team or domain) and “public” (an intentional interface, shared with other teams). Other groups and projects can only ref a model — that is, take a critical dependency on it — in accordance with its access.”
Models access can have one of three properties:
- private: Model can only be referenced within the same group
- protected: Model can only be referenced within the same package/project (this is the default)
- public: Model can be referenced by any group, package, or project
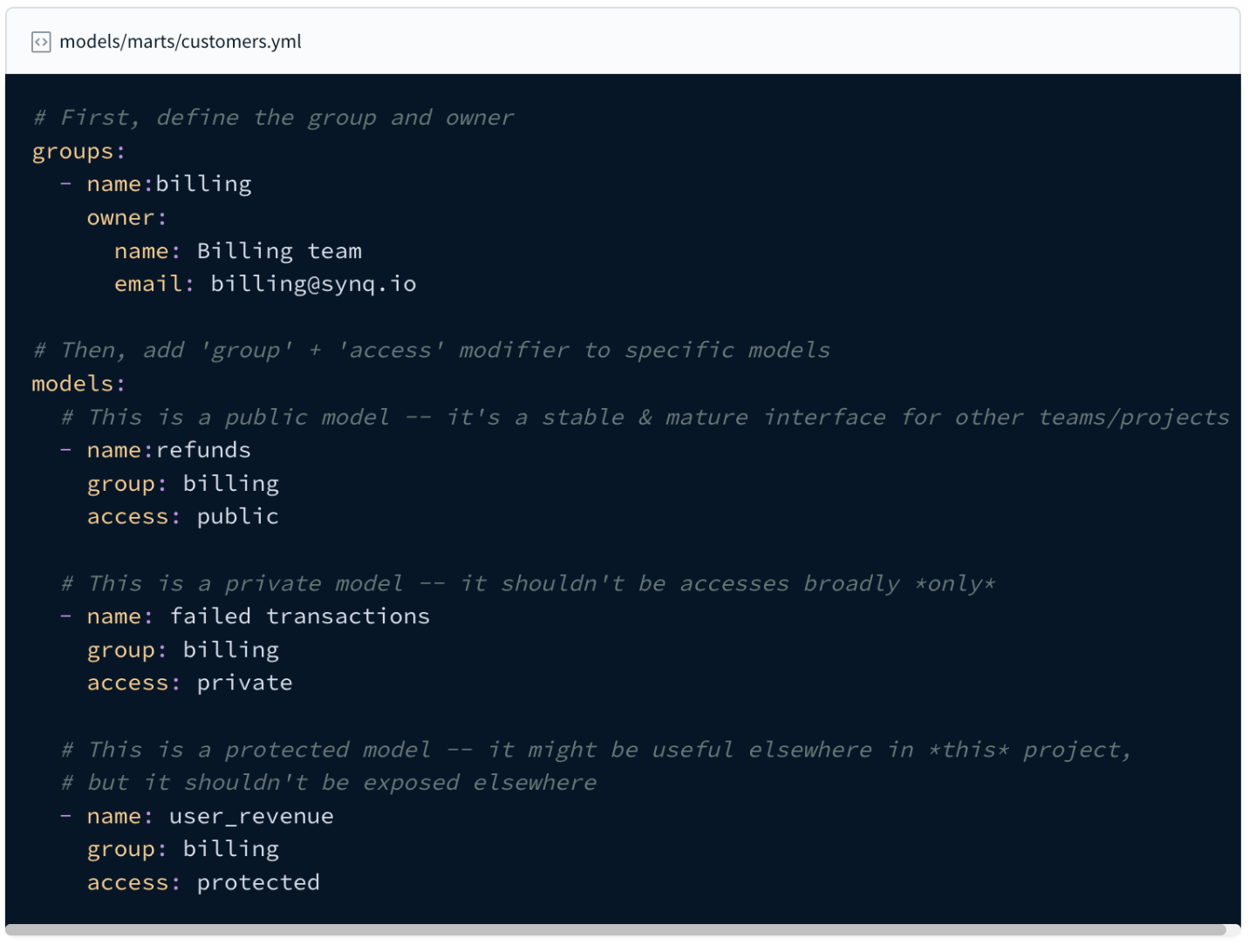
The combination of groups and access helps more closely encapsulate what is private to a domain and what should be exposed for everyone to use.
“If you work in the billing team, you can toggle a switch and only see models from other domains, which are well maintained and reliable to use. This narrows down the potential of dependencies you need to know about by 90% and speeds up your workflow, while also ensuring that data reliability is built in by design”
This concept gives a new lens to the lineage. Instead of seeing hundreds of models that are not relevant to you, you can filter only to see those where the owner has decided that they have high enough confidence in the quality to expose them for others to use.
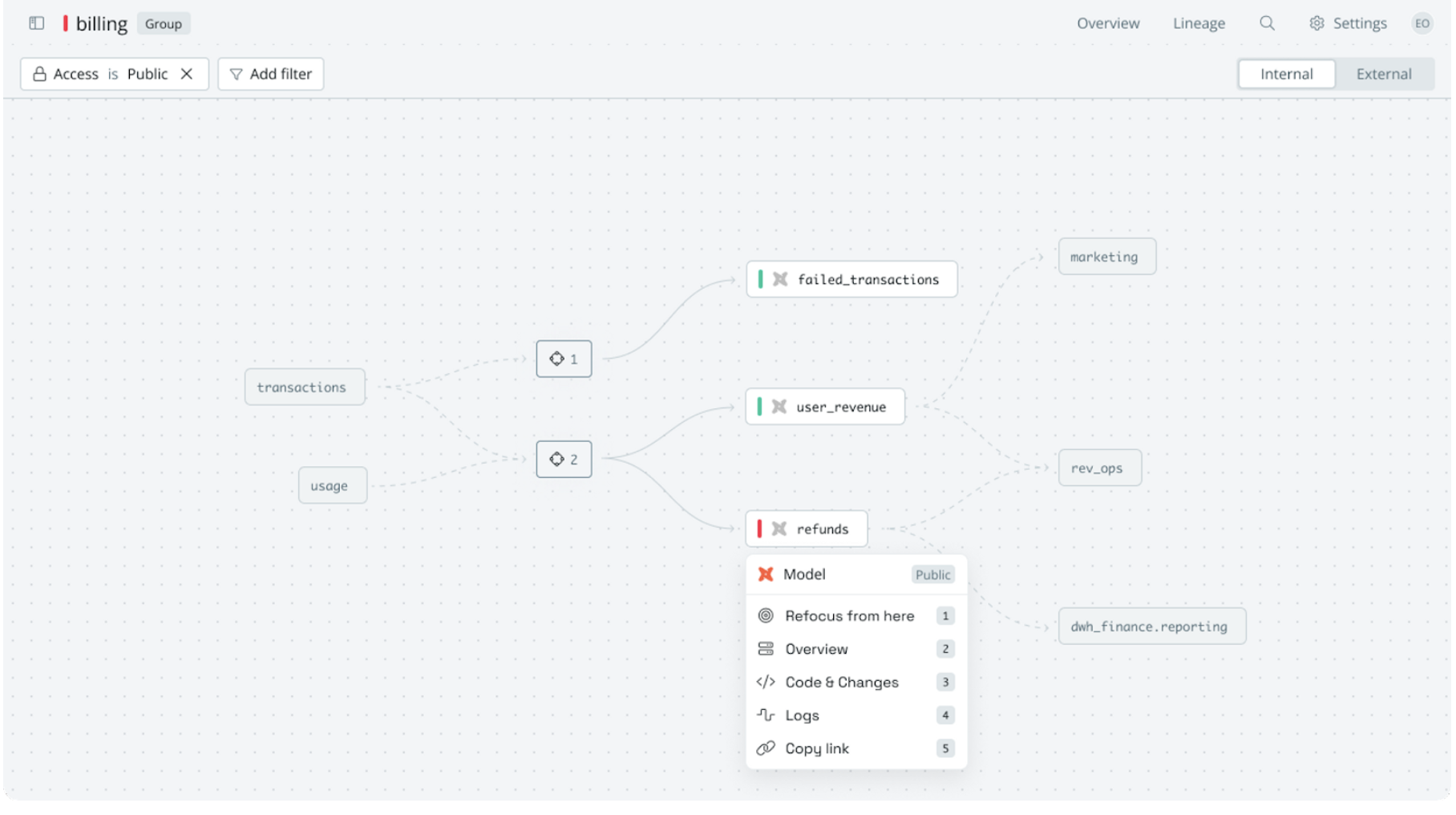
These concepts enable new ways for supercharged lineage workflows that work with scale
- Aggregate lineage nodes into groups to see which groups depend on you, and who you depend on
- Automatically notify a group in Slack if someone makes an upstream change that impact models they own
- Summarise downstream impact by groups for a comprehensive overview of who’s impacted before making a change
How do you know if you’ve succeeded
There’s no set finish line to being able to confidently say that you’ve a lineage that’s fit for scale. In our experience, if you can answer “yes“ to the following questions you’re doing better than most
- Do I confidently know the downstream impact of a data issue within minutes of learning about it
- Can I identify if critical assets are impacted before making a change across data models, dashboards, and other important assets
- Can new joiners meaningfully get value from the lineage within one month of joining
If you work with a larger data stack and have run into issues with making the lineage useful at scale, I’d love to speak with you. Get in touch at mikkel@synq.io

.png)
.png)