Why incidents must be the basis of data reliability SLAs


Until recently, incident management was solely the domain of software engineers, working together to return business-critical systems to a healthy state as quickly as possible. Now – as data takes a more central role in business processes and becomes business-critical in itself – incident management must be adopted by data teams too.
But the idea of incident-managing data could set alarm bells ringing (quite literally) throughout the data team. They could easily imagine getting a 3am pager alert from one failed dbt test. Or every minor data stack error being declared as an incident.
That’s why it’s vital to draw a thick and solid line between issues and incidents. And to ensure data reliability SLAs are based on the latter rather than the former.
Not every issue is an incident
As a data engineer you instinctively know there’s a big difference between minor issues and major incidents. A single failed dbt test might be critical, but that’s often not the case. You know, for example, that a test on a core model is going to be more important than a test on a fresh model added just yesterday.
So, how do we delineate between issues and incidents?
The incident management process has four key steps – detection, triage, handling and analytics. You can read more about them in our article about Synq’s approach to incident management.
At the detection stage we’re still talking about issues. The system should detect the issue quickly, alert the right person, and make sure they have all the context. Then, at the triage stage, that person assesses the scope and severity of the issue, and determines what datasets are impacted. Only at this point can they decide whether or not to declare an incident.
Issues detected across the stack are not incidents. An incident can only be declared by a human after they have assessed the severity of the issue.
This distinction allows teams to separate severe issues from minor ones that don’t need complete incident treatment. It is also an essential aspect of analytics and reporting and is the way software engineering teams work.
Incident data is a rich foundation for analytics
Rich incident data is an excellent foundation for analytics. Instead of counting every single (sometimes minor) issue as an incident, incidents that are explicitly declared by a person are a more solid foundation for the calculation of system SLA, uptime, and general quality.
At Synq we feel really strongly about this because we’ve seen the same practice in software teams. At any point, most sufficiently complex software systems have at least some minor failures, which are likely to auto-recover or can wait to be fixed. But this doesn’t mean the system is down or doesn’t work.
Without human judgment almost every software team would be in a constant incident state. This is certainly not a picture we want to paint for data teams, when our mission is to empower data teams to earn the trust they deserve, by equipping them with the tools they need to prove their value.
Separating issues and incidents is crucial. Calculating SLAs and uptime from issues is a terrible practice. They should be calculated from incidents declared by humans.
Separating issue- and incident-level analytics
By working with explicitly declared incidents in Synq we can calculate system metrics on two levels.
- At the issue level we can track internal metrics for the data team which is often called error budgets in engineering.
- At the incident level we can calculate system health, uptime, and SLAs based on declared incidents.
This approach is aligned with how engineering teams work, where the status page and system reliability metrics are managed in alignment with the incident management process.
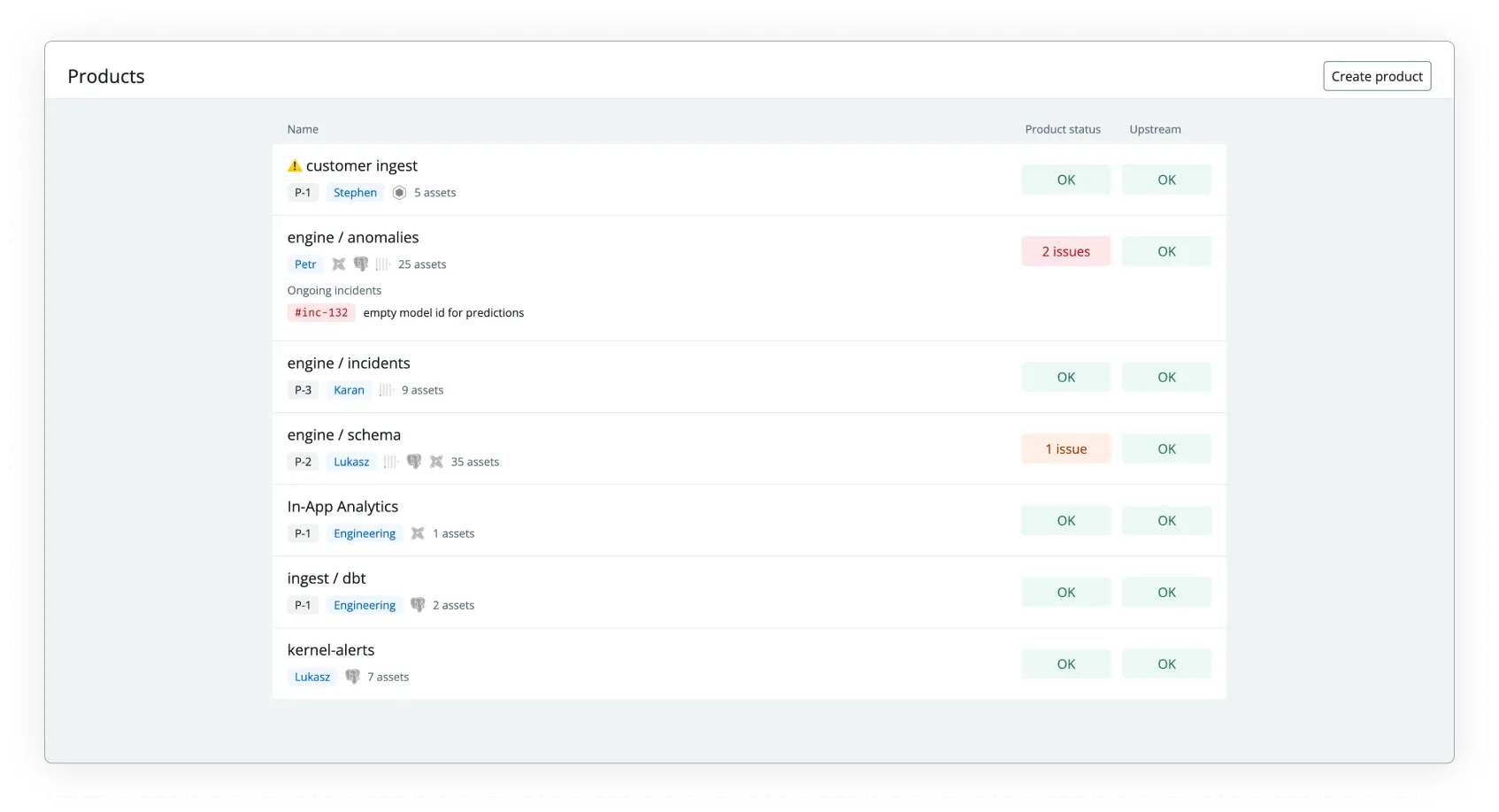
With this approach, our data product dashboards are becoming status pages of the data platform. We can highlight critical parts of the data platform, their current status, and the history of failures managed and announced by data teams.
Learn more by reading our article on Synq’s unique approach to the four stages of incident management.

.png)
.png)