Data ownership: A practical guide

dbt surveyed thousands of data practitioners asking: “What do you find most challenging while preparing data for analysis?”. 43% of the respondents answered that ambiguous data ownership was their biggest challenge, the highest percentage of all answers.
There are good reasons for this. As the data stack grows in complexity, it’s no longer possible for one person to keep everything in their head, and more often than not, the person who notices a problem is not the right person to fix it. Simultaneously, the number of upstream and downstream dependencies has exploded, making it challenging to locate the right upstream owner or notify impacted stakeholders.
Good ownership is easier said than done, and there’s no shortage of failed ownership initiatives. At Synq, we’ve worked with dozens of data teams on their ownership challenges. This post contains our learnings from what we’ve seen work well.
- Setting expectations for owners
- Defining ownership
- Notifying the right people with the right context
- Overcoming cultural ownership challenges
Setting expectations for owners
To some, being an owner means that you’re responsible for addressing issues on data assets owned by you. To others, it means that you’re responsible for notifying downstream stakeholders of issues or for data stewardship, tracking data quality over time, and making sure the relevant metadata is defined. You should make this clear. Without clear guidelines, each team will make their own interpretations. Expectations should be linked to the importance of the data asset (see Designing severity levels for data issues), for example:
- Low – add to the backlog to fix it by the end of the week
- Medium – let stakeholders know and fix the issue by the end of the day
- High – stop everything you’re doing to fix the issue right away
With expectations out of the way, we recommend you start by establishing an overview of your dependencies and the data controls you have in place.
You don’t have to ask many data teams to understand the dream state: A world where upstream producers own and manage the quality of their data, where the relevant data teams take responsibility, and where the days of stakeholders discovering issues are over.
But getting there is easier said than done. Breaking it into steps makes it clearer where you have gaps: (1) consolidate your metadata, (2) detect issues with relevant tests, (3) assign ownership, and (4) notify the relevant people of issues in a way where they can take action.
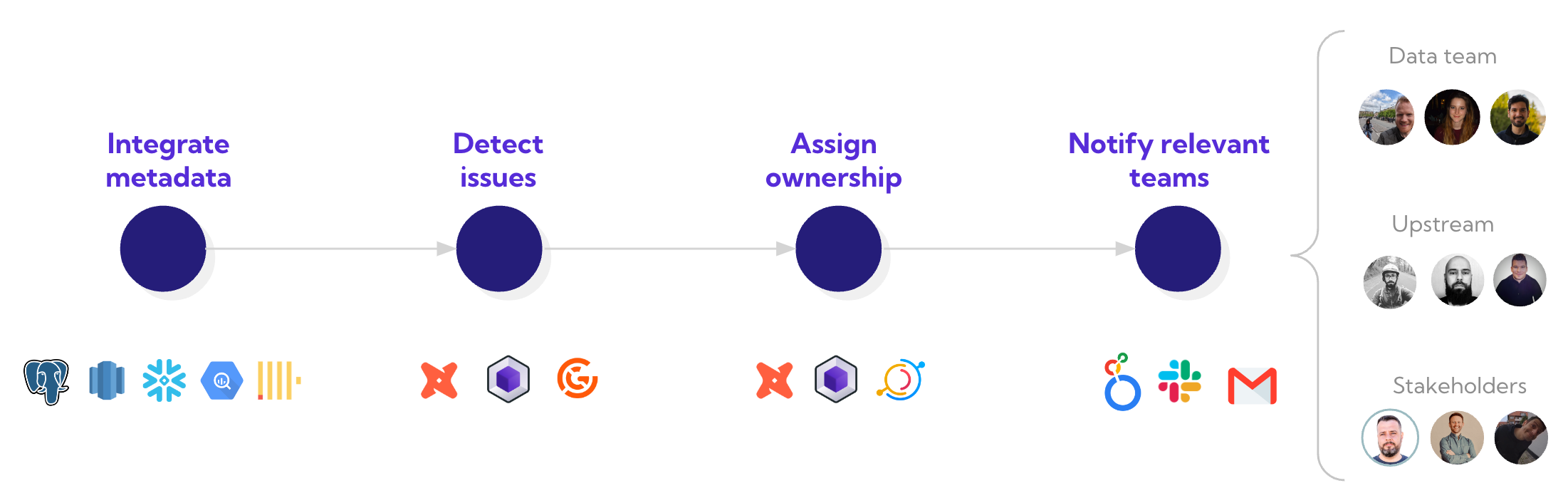
If you over-index on defining ownership without the relevant tests, you may do a good job notifying people but not proactively detecting important issues.
If you over-index on detecting important issues without ownership, alerts may get lost in the noise of a busy Slack channel.
You succeed only with the right combination of intentional testing and relevant ownership. For example, while a failing relationship test may not mean much to the owners of Salesforce customer data, knowing that a specific account ID has a creation date after the closing date is something they can fix.
Defining relevant tests to detect issues is a topic on its own (see our guide on anomaly detection and dbt tests best practices for more). Below, we will focus on defining ownership and notifying relevant teams.
Defining ownership
In the ideal world, you’d neatly group your stack into well-defined areas with clear boundaries. But in reality, ownership lines can get blurry, so don’t be discouraged if you can’t easily assign ownership to all assets. We’ll consider some of the most important considerations when defining ownership, such as defining ownership in code vs. UI, cross-tool ownership, and ownership across dependencies.
In theory – an ideal ownership map
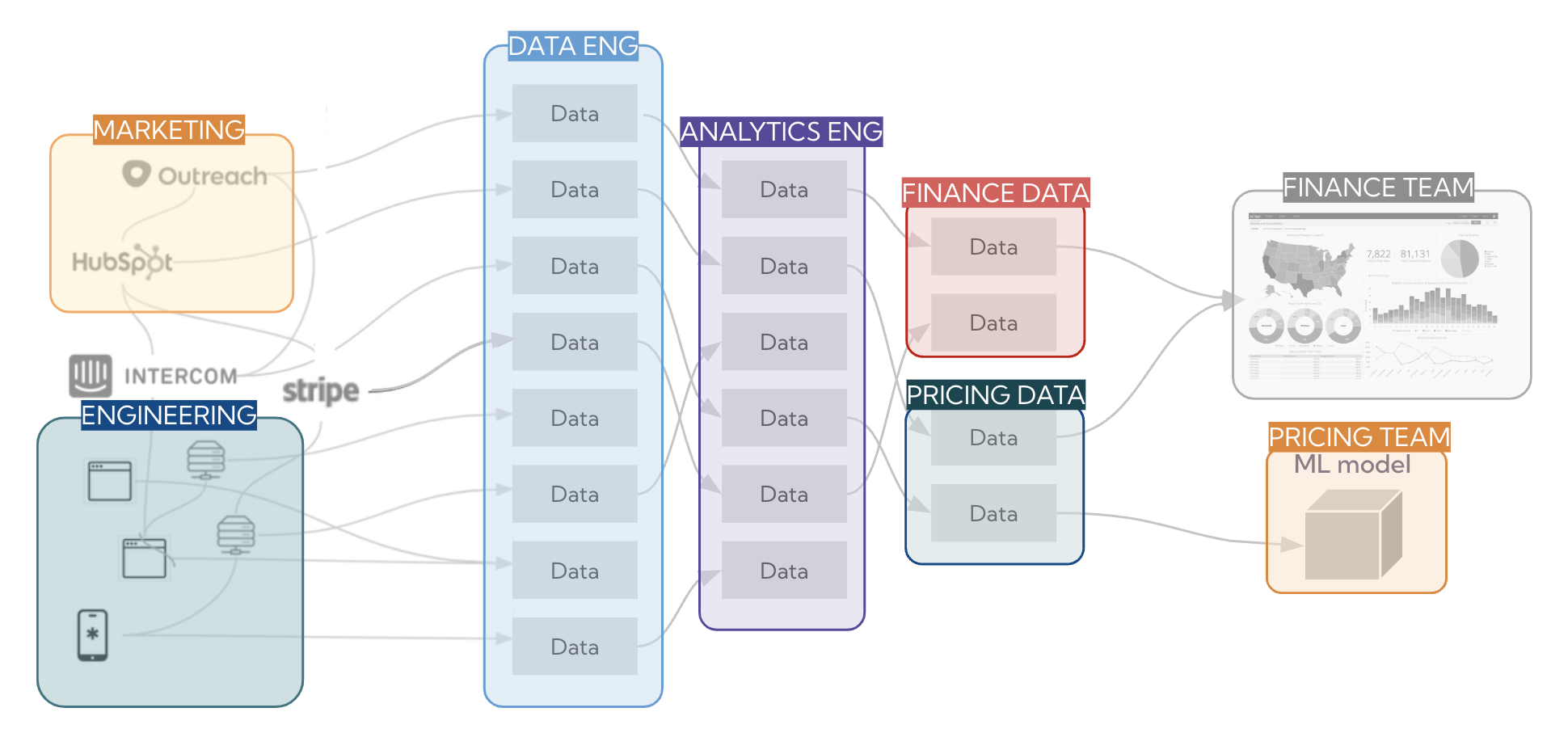
In practice – blurred boundaries
Use dbt owner meta tags
dbt has built-in support for designating owners using the meta: owner tag. Owners are displayed in dbt Docs, making it easy for everyone to see who’s responsible.
models:
- name: users
meta:
owner: "@alice"
model_maturity: in devYou can extend this to dbt sources to define ownership to upstream teams. If issues happen on sources before any data transformations, it indicates that upstream teams should own the issue.
An added benefit is that this approach lets you use CI checks, such as check-model tags from the pre-commit dbt package, to ensure that each data model has an owner tag assigned.
Use dbt groups to enable intentional collaboration
With dbt 1.5, dbt launched support for groups. Groups are helpful for larger dbt projects where you want to encapsulate parts of the internal logic only to be accessible to members of that group – similar to how you’d only expose certain end-points in a public API to end-users. If a model’s access property is private, only owners within its group can reference it.
models/marts/finance/finance.yml
groups:
- name: finance
owner:
# 'name' or 'email' is required; additional properties allowed
email: finance@jaffleshop.com
slack: finance-data
github: finance-data-teammodels/schema.yml
models:
- name: finance_private_model
access: private
config:
group: finance
# in a different group!
- name: marketing_model
config:
group: marketingUse existing folder structures.
This is a good option if you’ve already organized your dbt project or data warehouse schemas to resemble your ownership structure, such as marketing, finance, and operations. With folder-based ownership, you typically need less time to get set up, and as you add new data models, they, by design, fall into an existing owner group, reducing your upkeep. If you work with non-technical stakeholders who don’t contribute to your code base, such as business analysts or data stewards, this approach makes it easier for them.
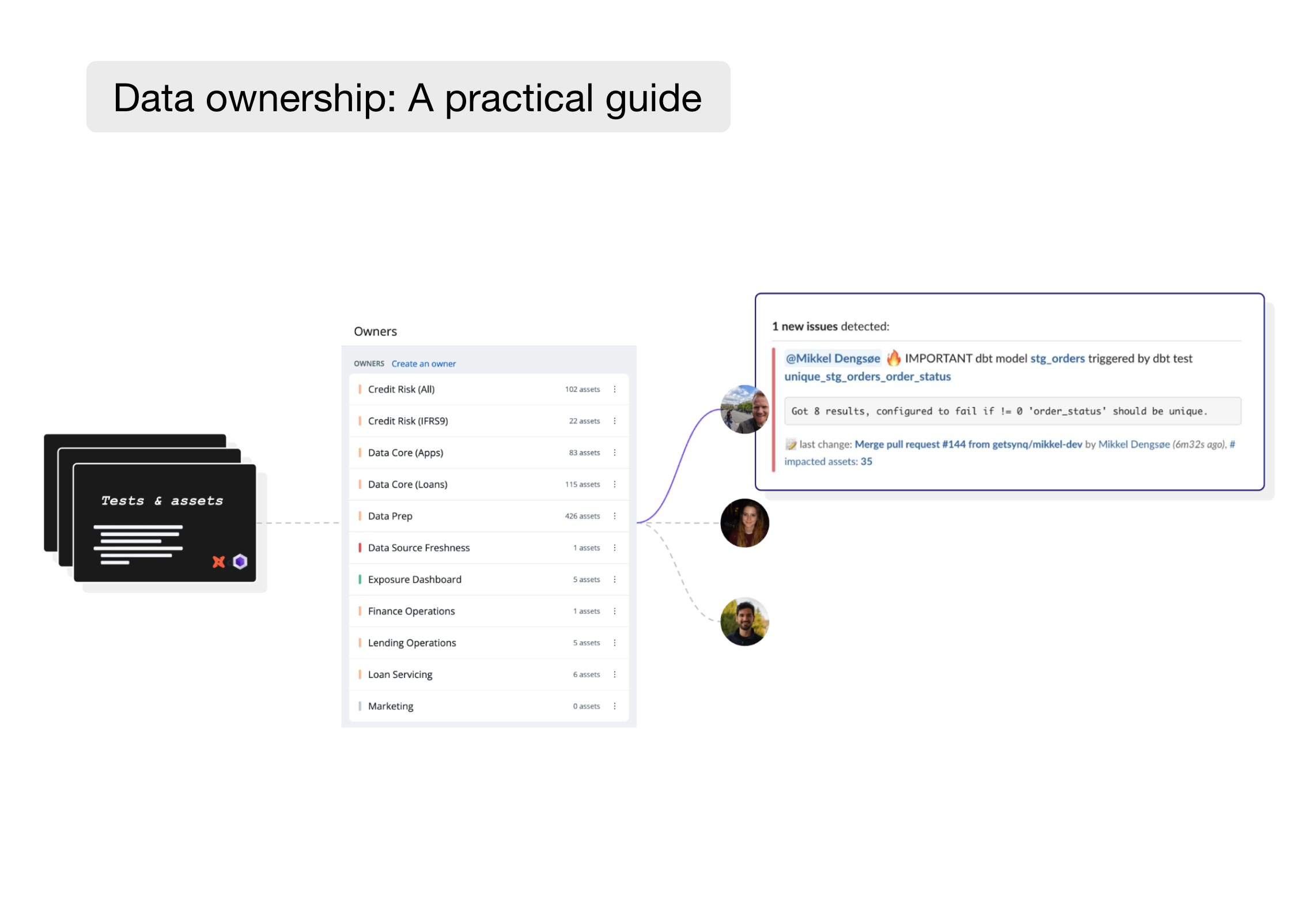
Assigning ownership by folder, setting a Slack channel and handle in the Synq UI
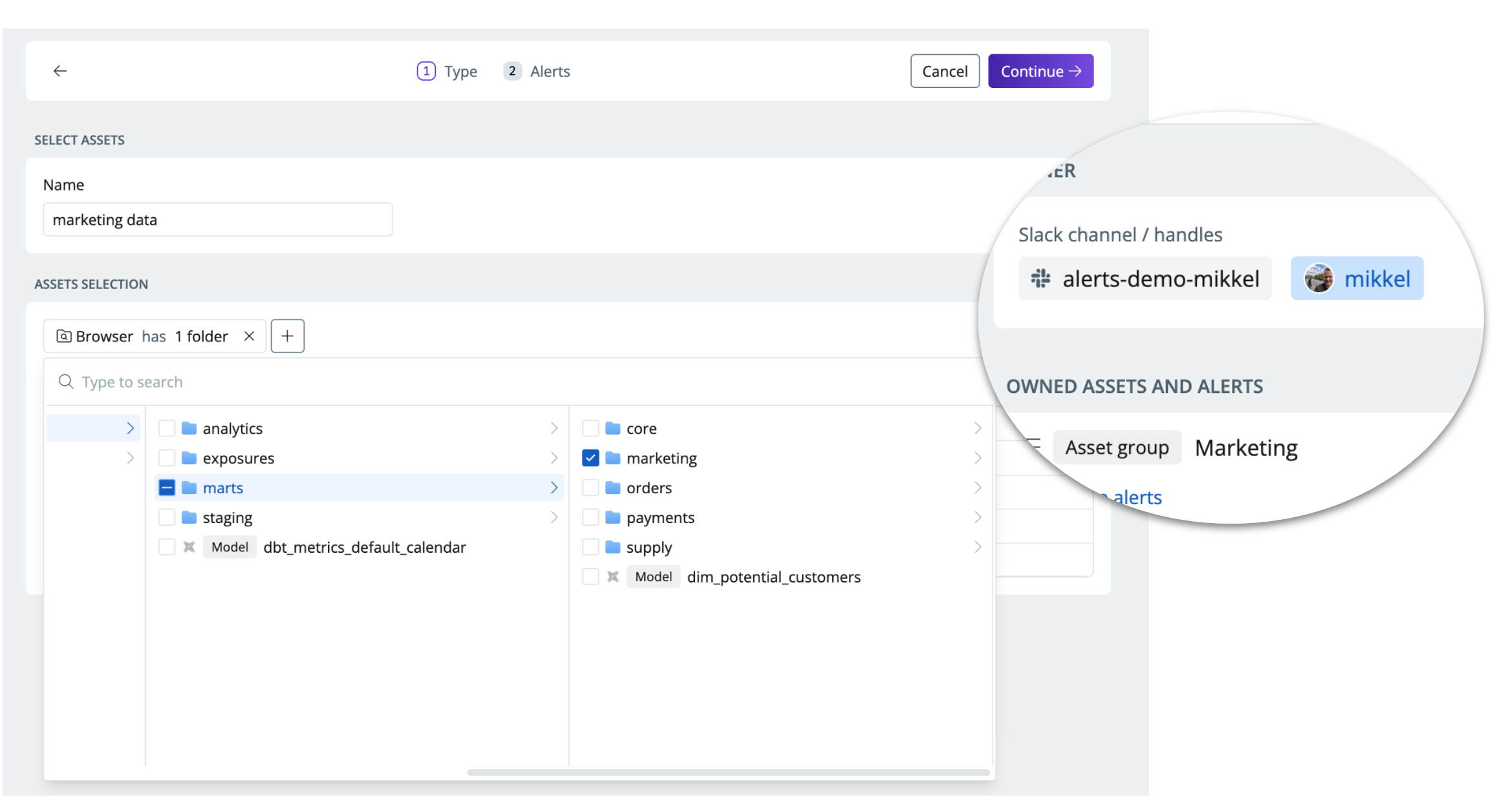
Defining cross-tool ownership
There are situations where you want to manage ownership across multiple tools – from databases to multiple data warehouses and dashboarding tools. This is useful when you want to find dashboards owned by specific teams or build out capabilities to notify downstream impacted stakeholders when you have a data incident. Managing cross-tool ownership in code can be difficult as there’s often no coherent way to define this.
Example of defining ownership across Looker, Clickhouse, Snowflake, and dbt in Synq
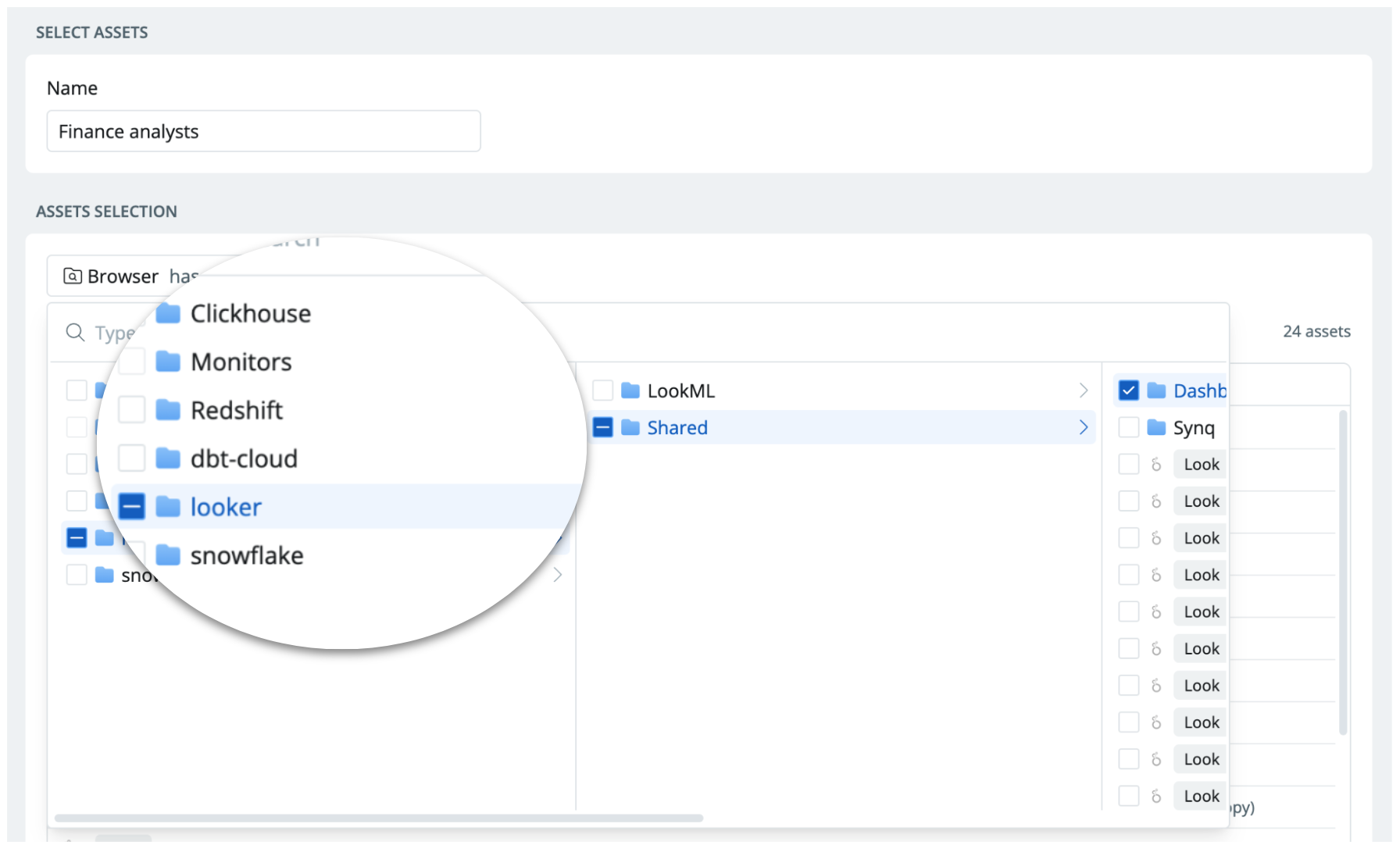
The end product of data is rarely limited to one chain in the stack. It’s almost always a constellation of upstream data sources, transformations, and end-user destinations such as dashboards. Data reliability is only as strong as the weakest link in this chain. When possible, we recommend managing ownership across the stack.
In the example below, the reliability of the dashboard is low despite any well-intentioned efforts made upstream.
- Rigorous logging of calls in the CRM (sales ops) = high →
- dbt models with high test coverage (analytics engineer) = high →
- Unresolved errors in the LookML code of a dashboard (sales analyst) = low
A data product in Synq based on a dbt exposure. The owner, Engineering, automatically gets notified about issues on upstream sources and models.
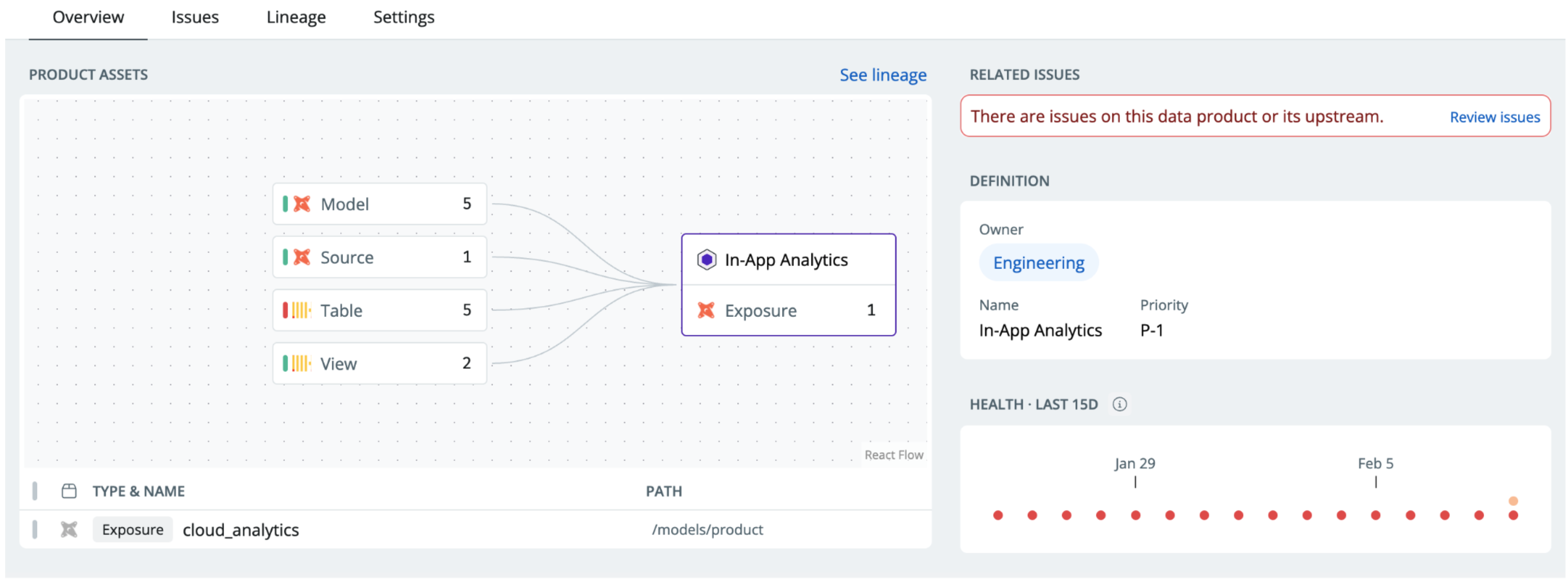
Notifying the right people with the right context
We recommend you consider data ownership holistically – from data sources owned by upstream teams to dashboards owned by end-users. For simplicity, we’ll group our recommendations into these groups: (1) data team, (2) upstream teams, and (3) business stakeholders.
Managing alerts within the data team
Managing ownership within the data team is the most straightforward. Your team is in control; typically, the tools are within the stack you manage. You can use your existing ownership definitions to ensure the right owner knows about the right issue. The two most effective ways to do this, assuming you use a communication tool like Slack, is by tagging owners and routing alerts based on your ownership definitions:
- Tagging owners – associate owners with Slack handles to tag groups or individuals and drive awareness of issues.
- Routing alerts – tie Slack channels with ownership and send alerts to the relevant team’s channel. This is a great way to overcome alert overload in the central channel.
Alerts are being routed based on ownership and tagging the owner.
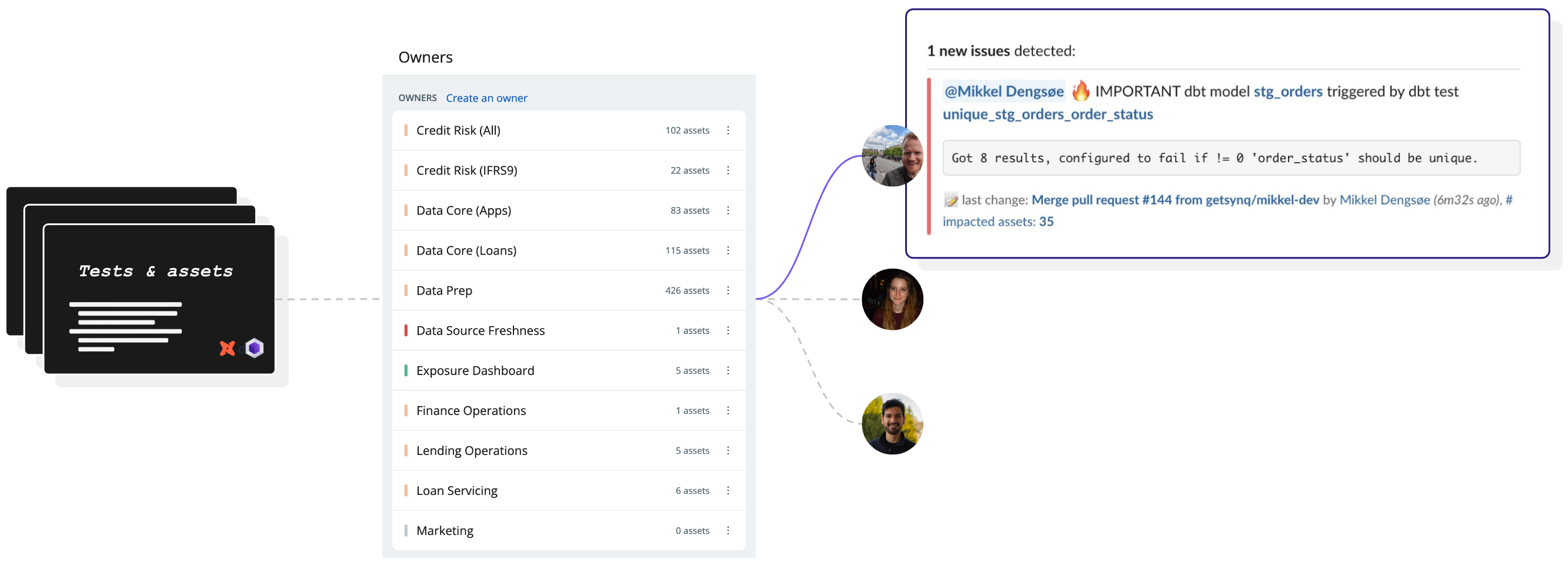
Notifying upstream teams
Getting upstream teams to take ownership of the quality of their data is every data team’s dream. Issues here are far from the data team’s control and are often the most frustrating to debug.
Books have been written about this topic, and concepts such as Data Mesh and Data Contracts have gotten a large following, largely due to how much this problem resonates. However, these can be time-consuming and difficult to implement, so we’ll focus on simpler, easier steps to bring awareness of issues to upstream teams.
We typically see two kinds of upstream teams that need to be alerted differently: technical teams, such as engineering, and non-technical teams, such as a SalesOps team owning Salesforce customer data.
a. Technical teams – the alerts you send don’t need to look different from those in the example from the data team above. If you’ve placed tests at your sources and detected issues, engineers should be able to connect the dots between the source and the error message and trace back the issues to their systems. For larger teams with a clear split between teams that ingest data (e.g., data platform) and teams that produce data (e.g., frontend engineers), it can be helpful to compliment the error message with details about what event or service it relates to.
b. Non-technical teams – bringing ownership of quality of source systems to non-technical teams is underrated. Too often, tedious input errors such as an incorrect customer amount or a duplicate employee_id end up on the data team to debug, triage, and find the right owner. With the right context, these teams can start owning this without the data team being involved (we’re increasingly seeing data teams start to do this).
An example alert is being sent to an upstream operations team.
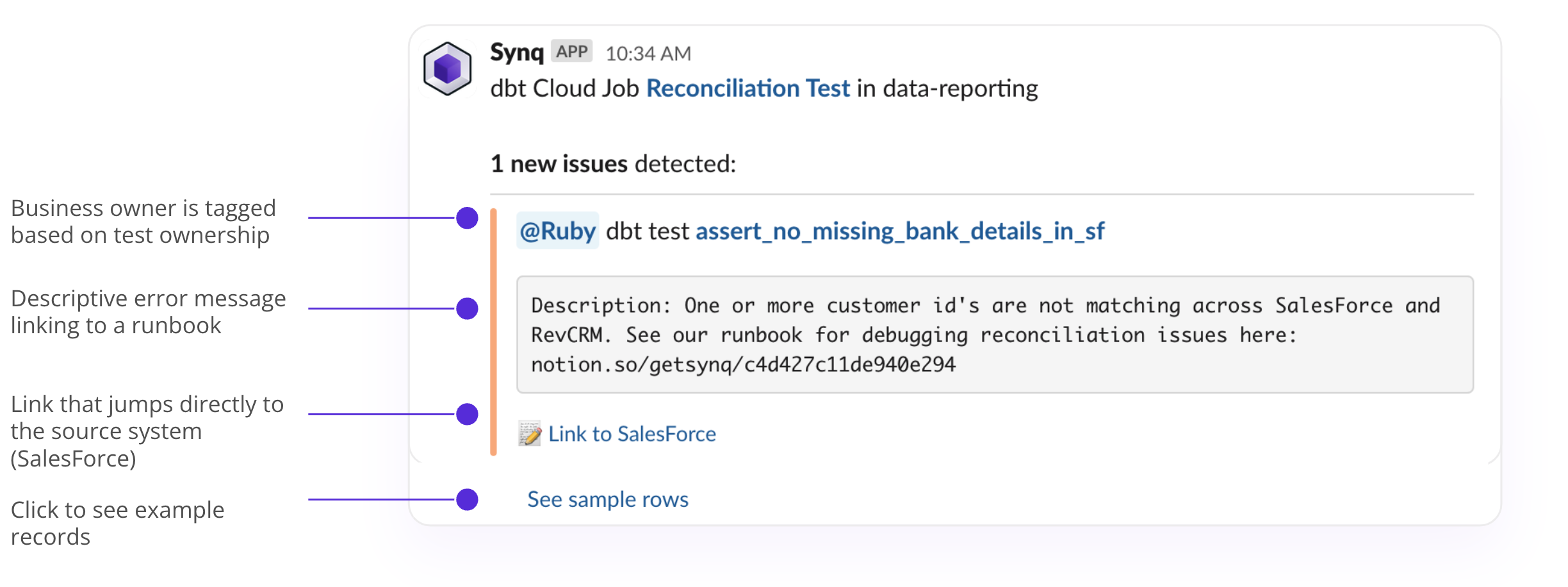
If done well, this will do wonders. The business owner is automatically tagged based on ownership of the test, and alerts are sent to a channel they monitor. The error message is descriptive and links to a runbook, a direct link to the source system, and a few example records – in other words, everything the non-technical team needs to take action without the data team’s input.
”Involve one team from the beginning. We found a team that was already proactively using data. You want a team that wants clean data to be the guinea pig” – Webinar with Rupert, data team lead at LendInvest.
Notifying stakeholders
Sometimes, you can alert your stakeholders to notify them of issues proactively. This works best if your stakeholders are data-savvy teams, such as a group of analysts in a business domain. But sending Slack alerts to your marketing director that five rows are failing a unique test on the orders data model is not the best idea.
In our experience, the best way to notify impacted stakeholders is for the person with the relevant context to “declare” it. An example is displaying an ongoing incident in your dashboard with an easy-to-understand description, a data owner, status, and the time the incident was declared.
Programmatically displaying an ongoing incident in a Looker tile
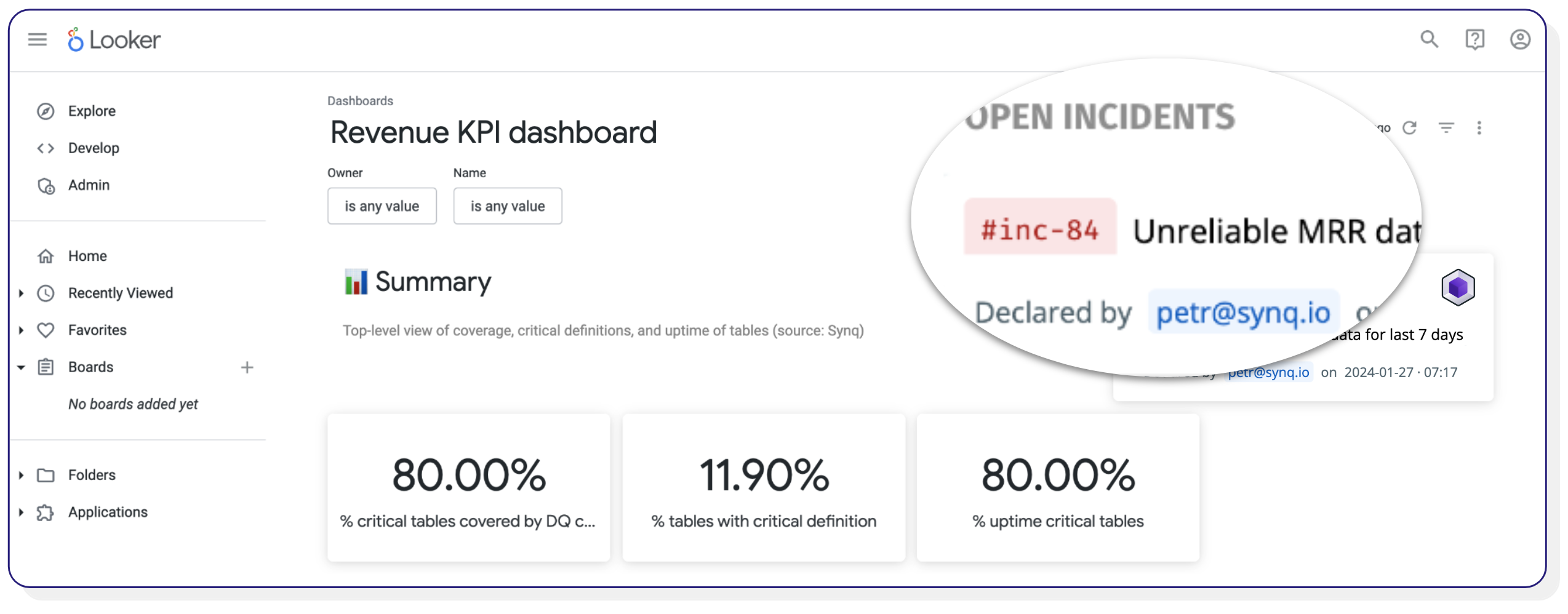
Doing this minimizes the risk that stakeholders rely on data with ongoing issues and reduces the work you need to do to send targeted Slack messages to impacted stakeholders.
Cultural ownership challenges
One thing is being assigned as an owner; another is being held accountable. Succeeding with ownership is as much a cultural challenge as a technical one.
Here are a few things to consider when you start your ownership journey.
Beware of assigning ownership on an individual level. While assigning ownership to individuals is tempting (e.g., John Doe), it’s often not the best idea. Individual ownership makes it harder to manage if the person leaves the company, moves teams, or goes on holiday. Instead, consider setting ownership to a group of people with a related understanding of a domain (e.g., @finance-analytics).
“One of our biggest data incidents happened when a person who’d left the company appeared as the owner of a critical data alert. Everyone thought it was being looked into, which created a false sense of security and left it unresolved for weeks” – Head of Data at a 100-person data team.
Senior buy-in is key for upstream ownership. To get upstream teams to take ownership of issues originating from their systems, you often need someone from senior management to buy in and help enforce it. People are busy, and the last thing they want is another inflow of alerts to pay attention to. Ideally, find someone with skin in the game whose key goals and objectives are impacted by recent data quality issues.
”Ensure you get buy-in from someone senior in the business and have them understand the business implications of data being wrong” – Webinar with Rupert, data team lead at LendInvest
Beware of the signal-to-noise ratio. Nothing kills good ownership intentions faster than alert overload. If you send an upstream team hundreds of irrelevant alerts, there’s little chance they’ll keep paying attention. Be mindful of alert overload and err on the side of sending fewer rather than too many alerts.
Be explicit about expectations. Make it clear what it means to be an owner. For example, for high-severity issues, owners must address issues within four hours, but out-of-hours monitoring is not expected. Without clearly defined expectations, the people on your team who care the most will implicitly end up owning most issues. Declaring incidents for data issues is a great way of bringing this transparency out in the open.
Start small. Too often, ownership initiatives are made overly complicated by excessive planning, only to fail when the rubber hits the road. Instead, start with one team or domain already motivated to do something about their data quality. Show some success, find out what works, and double down there.
Summary
Ambiguous ownership was the top-ranked answer when thousands of data practitioners were surveyed about their biggest challenges. There are good reasons for this. Data stacks have exploded in size and complexity, and no person can keep everything in their head. In this post, we’ve looked into how you can overcome this.
- Setting expectations for owners – be explicit about what’s expected of owners. For example, clearly state how low, medium, and high-severity issues should be addressed.
- Defining ownership – ownership can be defined in code or the UI. Defining ownership in code makes it easier to enforce that owner tags are present at CI, for example. Defining ownership in the UI makes assigning cross-tool ownership easier and brings in non-technical stakeholders.
- Notifying the right people with the right context – ownership should be managed across the stack, but data teams, upstream teams, and downstream stakeholders need different alerts.
- Overcoming cultural ownership challenges – ownership is as much a cultural challenge as a technical one. Start small, find a team where you have senior buy-in, and beware of alert overload.
If you want to discuss ownership challenges or learn about best practices, get in touch

.png)
.png)