Activating ownership with data contracts in dbt

Data contracts have been the talk of data town for the last year – and with good reason. Building high quality data is consistently top of the priority list for data teams. The most common data quality obstacle is upstream teams introducing unexpected errors such as changing the meaning of an event or renaming a column.
Data mesh, data contracts and shifting ownership to data producers has been presented as the solution. Data teams have largely brought into this promise but only a fraction can confidently say that they’ve seen the expected impact from their efforts. One of the reasons for this is that contracts introduce yet another technical and organisational burden for already stretched engineers.
With dbt 1.5 and the support for data contracts, data teams have the opportunity to roll out contracts themselves. While it doesn’t solve the full problem it provides a way to enforce quality at the intersection of teams that can be rolled out in days instead of months.
In this article we’ll walk through
- Why (and why not) to use data contracts
- How to implement data contracts in dbt 1.5
- Activating ownership with dbt tests and data contracts in Synq
Why do we need data contracts
Once data teams start to implement testing and alerting on the data warehouse they realise that the majority of issues can be traced back to upstream sources and teams.
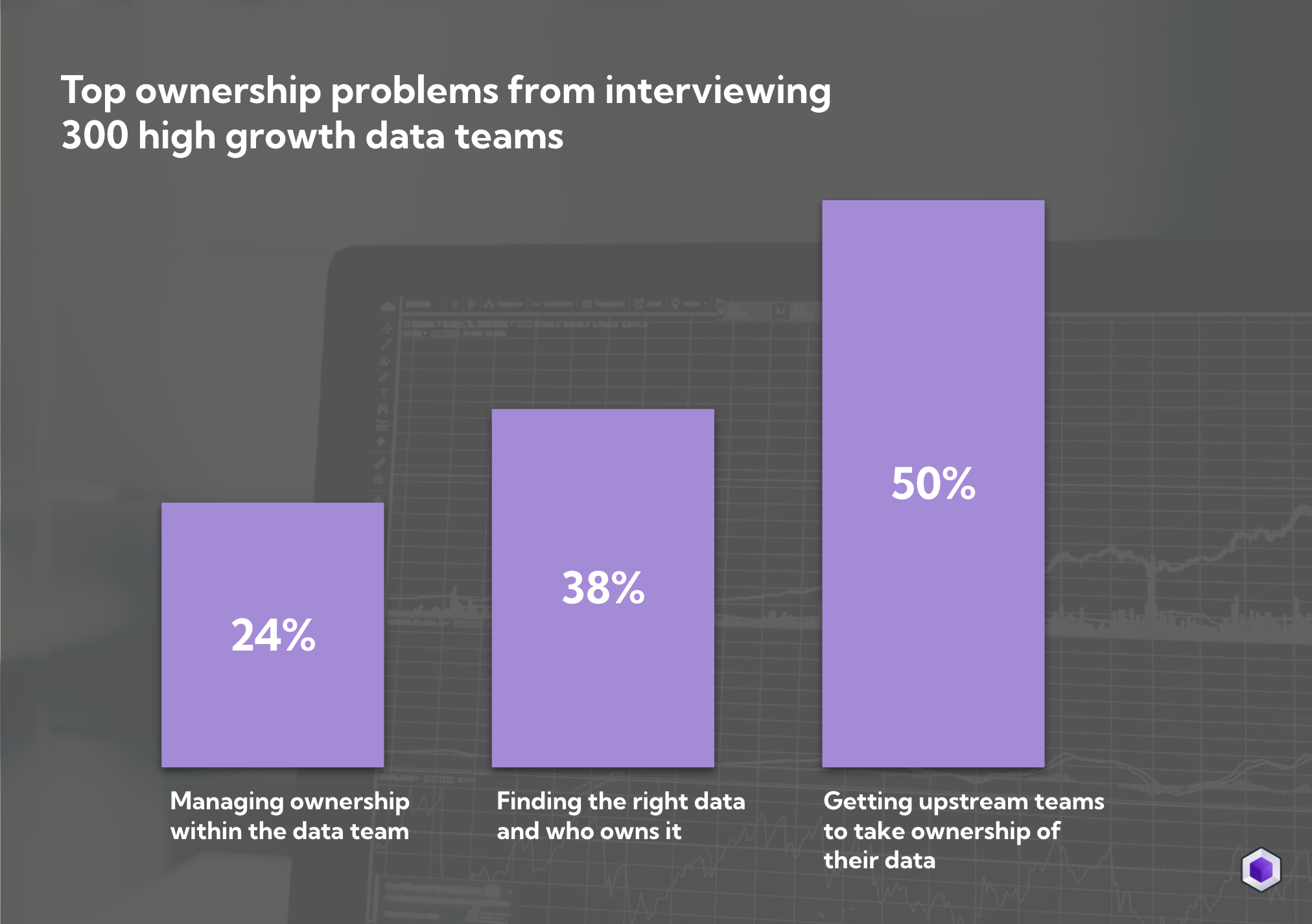
Issues introduced by upstream teams are often particularly painful and have magnifying effects such as
- Data consumers using wrong data as upstream teams unintentionally introduce issues
- The data team ending up spending most of their time working reactively dealing with dozens of data alerts
- Time wasted chasing upstream teams and trying to find the right owner
“Because data producers never agreed to manage data quality on behalf of analytics, ML, or other data-centric use cases they quickly run into a ‘fire alarms without a fire-department situation.’ We become great at detecting problems no one has the capacity to fix.” – Chad Sanderson, COO of Data Quality Camp
Data contracts are similar to an API agreement between upstream engineering teams who own production services such as instrumentation of events in a mobile application and data teams who are consuming the data downstream. With data contracts teams can agree on the shape of data across schematic and semantic dimensions. For example, a field containing a phone number can be defined to only allow for integers or a customer_id field can be defined to never be null.
With a contract, at least in theory, engineering teams are now enforced to provide data that conforms with rules they’ve agreed to — and thus hopefully saving the data team a lot of hassle down the road.
Why contracts are hard in practice
Many data contract initiatives get stuck at the drawing board, take much longer than initially planned and fail to have the intended impact.
The problem is twofold
- Technical – there’s no set technical framework for how data contracts should be designed or implemented and they end up on the backlog of already busy engineers
- Cultural – engineers are often not incentivized to care about an entirely new set of alerts and issues from data systems they don’t always feel directly responsible for
Where should data contracts sit
Most data contracts initiatives focus on the contract between upstream data producers and data teams. The contract is enforced before data is ingested into the data warehouse and creates explicit rules to prevent data that’s in breach of the contract from being ingested. But contracts can also be created at intersection of data models.
Data contracts at the engineering system level
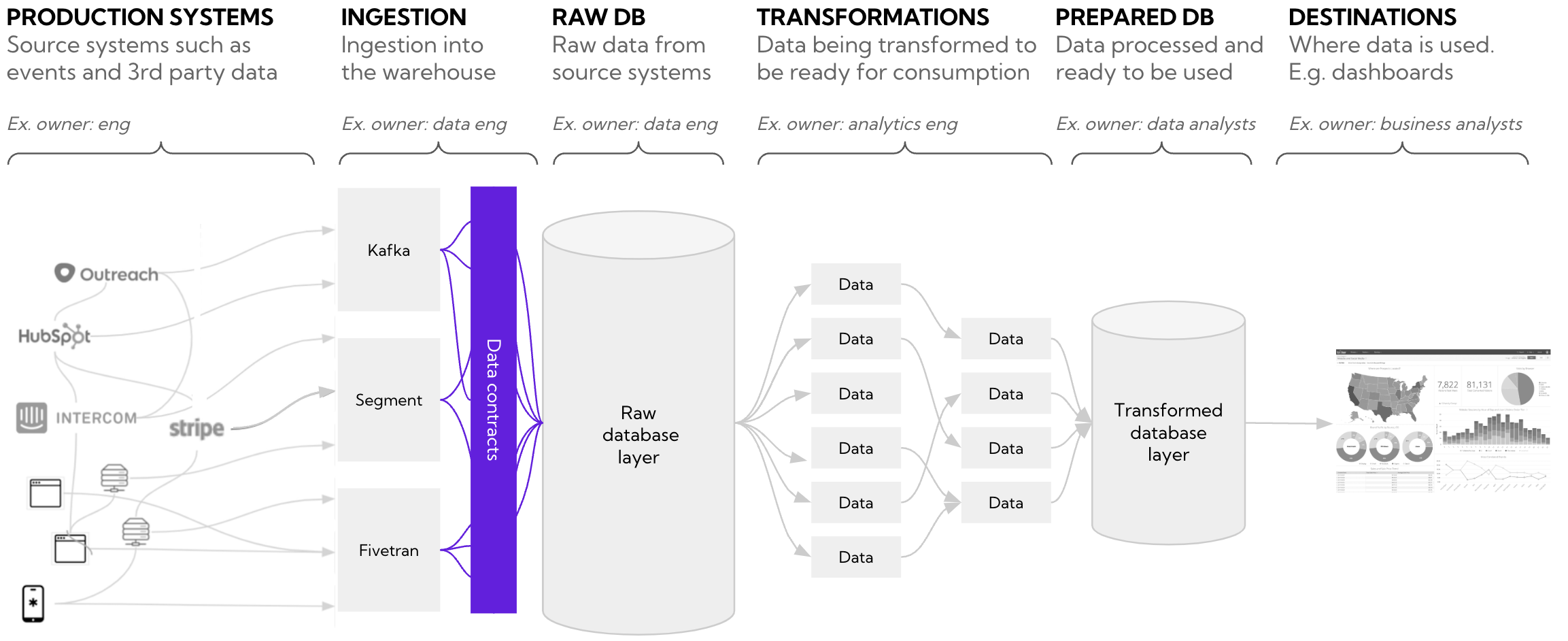
Contracts enforced at the engineering system level has several advantages
- Enforce upstream quality – they enforce data contracts at the producer level so that no data that’s in breach makes it into the data warehouse. This improves data reliability and keeps you from having to reactively fix issues in the warehouse
- Enforce ownership – data ingested into the warehouse can be set to require metadata such as owner, SLA levels and other properties to improve accountability
- Creates a shared culture of quality – when engineers can see that making a change has an effect on data models that are business-critical, it helps build a culture of appreciation for shared ownership of data quality between producers and data teams
But it also comes with some drawbacks
- Difficult implementation – the engineering team needs to commit to building out and maintaining the data contract layer
- Long time to value – once contracts are set up you need to invest in educating upstream teams of the potential impact of issues introduced by them to foster a culture where they start to take ownership of the quality of data they produce
- Can reduce development speed – in the worst case scenario adhering to data contracts slows development speed for engineers which makes it harder to get the continued buy-in
Data contracts within the data warehouse
Another option is defining contracts within the data stack to explicitly tell downstream consumers that they can rely on upstream data. For example, if you own everything in models/regulatory_reporting and that relies on models in models/users you benefit from being ensured that these data models will be correct.
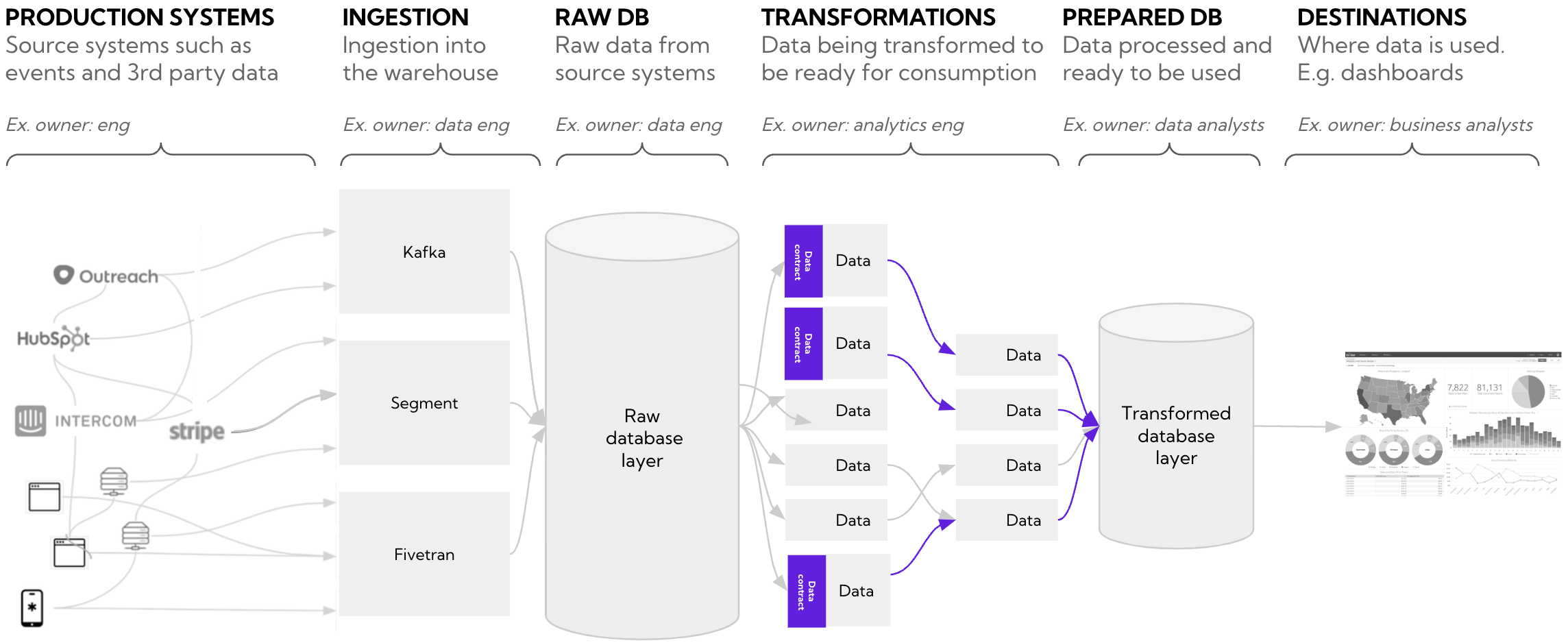
Model-level contracts have several advantages
- Easier to implement – maintain contracts within dbt that your data team already use and know without needing to involve engineers or the platform team
- Improved data reliability – as a consumer of data that sits downstream from other data models you’re guaranteed that the output data is reliable and adheres to predefined standards
- Faster debugging – model contracts simplify the debugging process by enforcing constraints during the build process. If you have a build failure due to a constraint violation, you can quickly pinpoint the issue and address it before it impacts downstream processes
But also comes with some disadvantages
- Not a clean shift of ownership upwards – in its basic form, this type of data contract doesn’t fully address the problem of preventing issues originating from upstream engineering teams
- Wrong data can go into the warehouse – if contracts are not specified at the ingest layer you may end up with incorrect data in the data warehouse that’s harder to clean up later
- Limited platform support – not all data platforms support and enforce all of the constraints that dbt model contracts might require. This limitation can result in a false sense of security and the contracts not being as effective in maintaining data quality
In summary, both approaches have pros and cons but there’s no reason why you can’t combine them to enforce quality upstream and within the data warehouse.
Activating ownership for data contracts and dbt tests with Synq
In a perfect world you’d have data contracts in place for all services that are ingestion business-critical data so only data that conforms to standards you’ve defined enters the data warehouse. But there are many benefits to starting with contracts within the data warehouse.
It is easier to make the case for contracts in your production services if you already have a culture in place of monitoring and being on top of quality within the data warehouse. By having model-level contracts in place you can report on how many issues come from upstream services, and make an informed argument for rolling out contracts on these.
In this section we’ll show how to build a system fully managed by the data team to start harnessing the benefits of data contracts. If you can make this work, you may realise it’s already fit for scale, or you may decide that you need to implement contracts that are more tightly coupled to production services. But at least you’ve proven out that you can get the benefits in a more fast paced and iterative way.
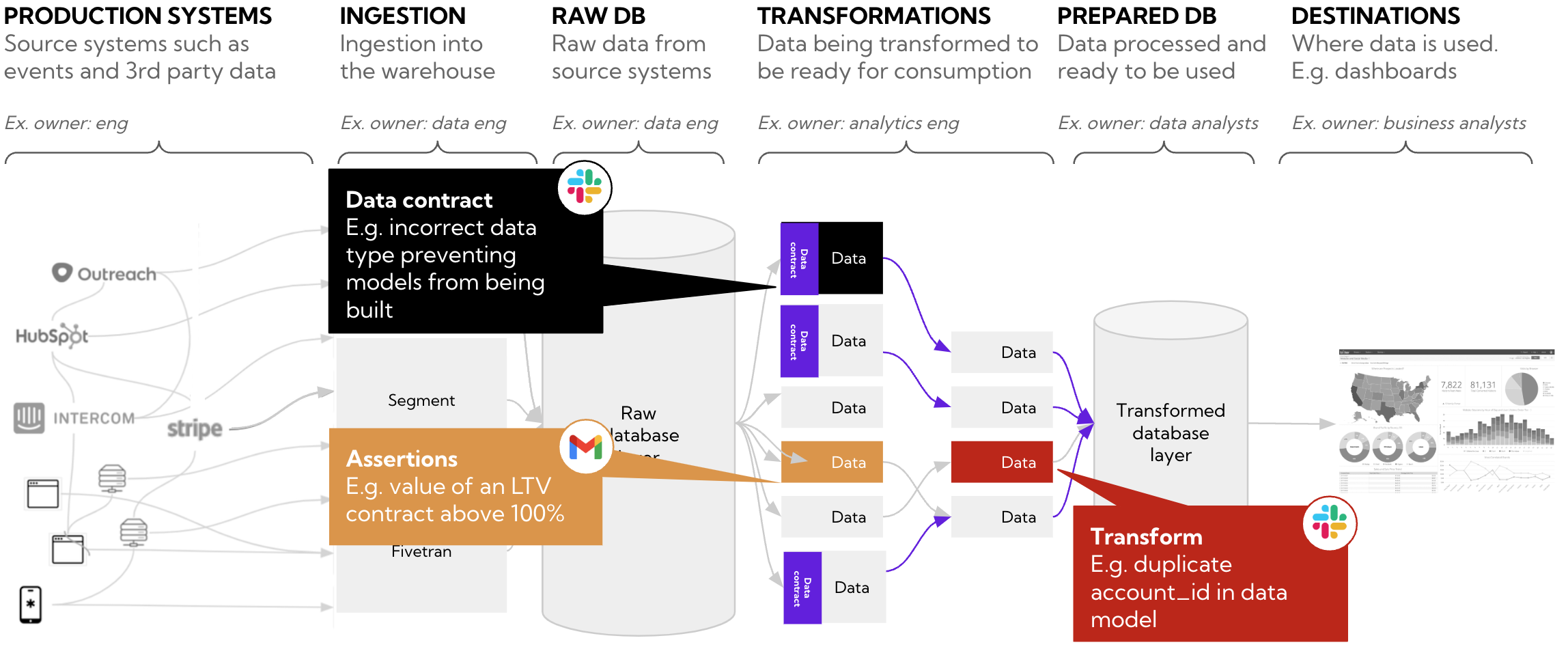
The system consists of three distinct quality boundaries that alert the relevant team when there are breaches.
- Data contracts (engineering): dbt 1.5 is used for data contracts to enforce schema consistency and rudimentary semantic checks. Blocking changes prevents dbt from building when there are violations and the upstream engineering team is alerted of contract failures
- Assertions (business team): Our system relies on operational data used by a business team. Sometimes operational inconsistencies mean that customer lifetime value (CLTV) is calculated incorrectly and the team is notified about these so they can take the necessary steps to fix them
- Transformation tests (data team): The data team is alerted of critical issues that are not related to data contracts or business assertions such as failing uniqueness tests from dbt
Implementing data contracts in dbt 1.5
Model-level contracts in dbt differ from tests in two fundamental ways
- Tests are run after a model is built, whereas contracts are run before a model is built. This means that models under contract will never be run if the contract is violated making the confidence of their accuracy higher
- If you remove a column in an SQL file and the yml is under a contract then dbt will break if a column is missing. Breaking changes include removing an existing column or changing the
data_typeof an existing column
Data contracts are implemented in dbt through a series of constraints that can be applied at the model or column level. There are two types of constraints.
- Semantic – can be any of not null, unique, primary key, foreign key or a custom expression to enforce that the data conforms to expected behaviour
- Data type – such as string and integer to ensure that the data conforms to the data type you expect
Not all semantics are enforced by all platforms. You can see which platforms support what constraints in the dbt documentation.
Compilation Error in model stg_customers (models/staging/customers/stg_customers.sql)
This model has an enforced contract that failed.
Please ensure the name, data_type, and number of columns in your contract match the columns in your model's definition.
| column_name | definition_type | contract_type | mismatch_reason |
| ------------------ | --------------- | ------------- | ------------------ |
| customer_id | STRING | INT64 | data type mismatch |Example compilation error from dbt logs from schema data type violation
If we put it all together, here’s how the stg_customers model looks when enforced under a data contract. Both owner and eng-owner has been set as a way of determining which team to alert on issues.
models:
- name: stg_customers
config:
contract:
enforced: true
description: All customers
meta:
eng-owner: "platform-eng"
owner: "analytics-eng"
criticality: high
columns:
- name: customer_id
data_type: int
constraints:
- type: not_null
description: Identifier for customer
- name: customer_city
data_type: stringTesting business assertions
While data contracts prevent the model from being built altogether, dbt build can also be configured to skip downstream dependencies in case of an upstream test errror. But sometimes you have errors that are worth bringing to the attention of other teams without blocking downstream dependencies from running. In our example, if the customer lifetime value is above 100% we know there is a logical error and that the operational team has to fix it in the underlying system.
You don’t need a contract to enforce this, and likely don’t want to prevent the pipeline from running. At the same time you don’t want the data team’s Slack channel filling up with alerts they’re not responsible for fixing. A better solution is to route these alerts directly to the team responsible.
By using dbt tests with severity warn and a dbt utils or a package such as dbt expectations you can capture a lot of this type of business logic in code and with the meta owner configurations, route it to the relevant team.
models:
- name: fct_lending
description: Lending data by customer
columns:
- name: customer_id
description: Identifier for customer
- name: customer_ltv
description: Estimated LTV for the customer
tests:
- dbt_utils.expression_is_true:
expression: "> 1"
tags: ["lending-team"]
config:
severity: warnConsiderations when assigning ownership
Assigning ownership to the right upstream team can be difficult and may require some digging by tracing back from your raw data sources. To make matters more complicated, sometimes ownership is defined at the column instead of model level which can add to the confusion of who’s responsible when something goes wrong.
By keeping the definitions in dbt, you can neatly define ownership both at the table or column level in your yml files. You can use clear properties such as owner (data team) and eng-owner (engineering), and apply individual tags for business exceptions to make the divide clear.
When first getting started with contracts, it may be needed to dig in and speak to your engineering colleagues or look at the git history of model changes to pin down ownership. You can also use a data lineage tool to ease this process. For more details you can read our in-depth guide to Defining ownership and making it actionable.
Activating ownership with Synq
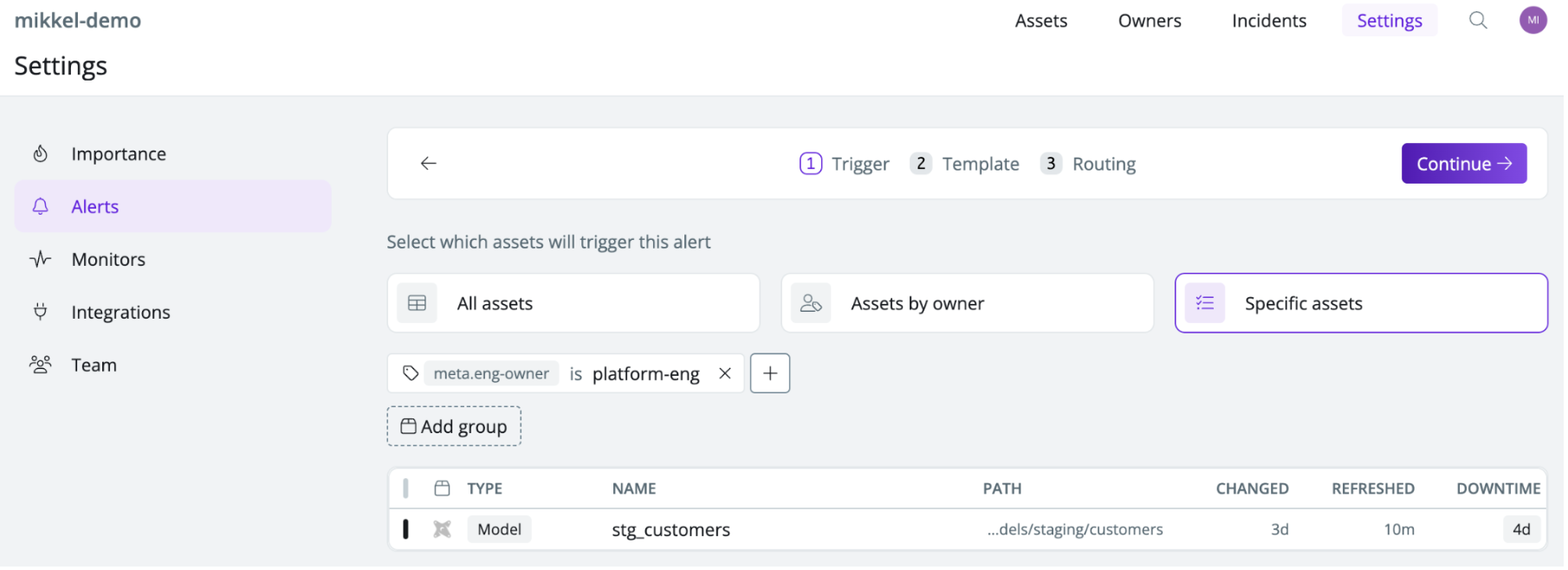
Alerting upstream engineering teams of contract breaches
In Synq, you can create an alert that’s triggered when contracts that have been tagged with meta eng-owner: platform-eng are breached and specify which channel to send the alert to.
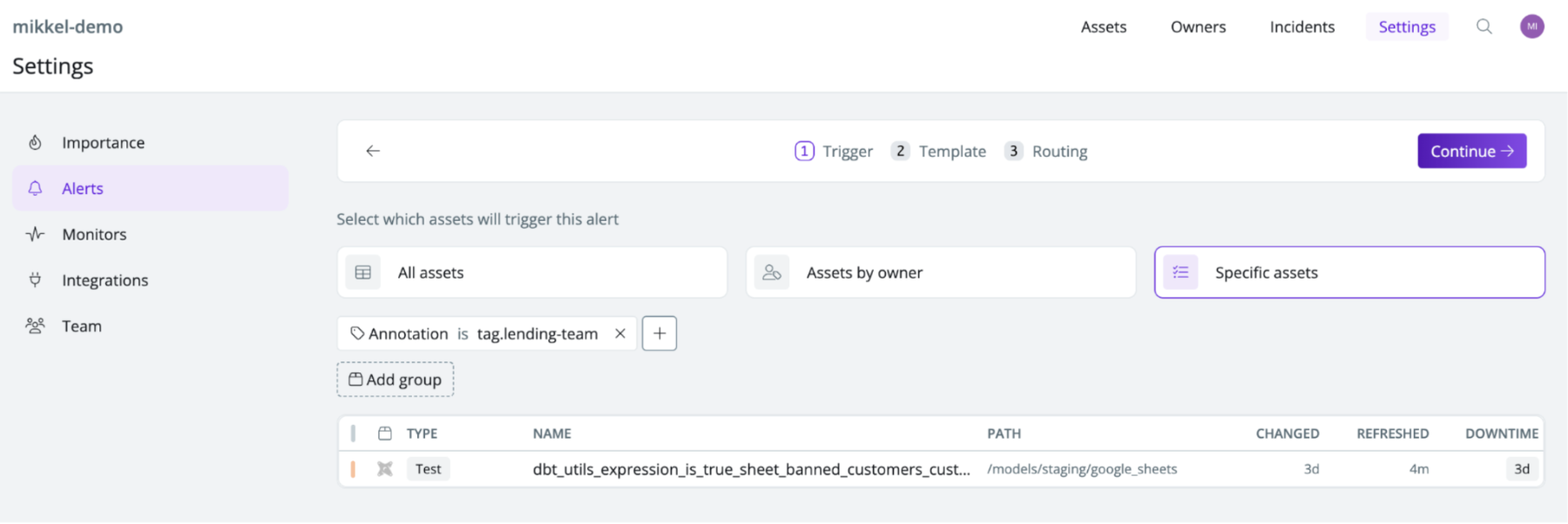
Alerting the operations team of assertion issues
Similarly, use the tag lending-team to route issues on specific assertion tests failures such as the customer lifetime value exceeding 100%.
For advanced use cases you can make use of dbt’s store_failures to write the result of test outputs to a table in your data warehouse. This can help less technical people get insight into which rows and unique identifiers have failed a test without having to run SQL code.
Send test errors on critical models to the P1 data team channel
Extend the alerting engine to send alerts on models you’ve tagged as critical to the #p1-data-issues channel. This helps the data team stay in the loop of both contract and assertion test issues when they impact important assets.
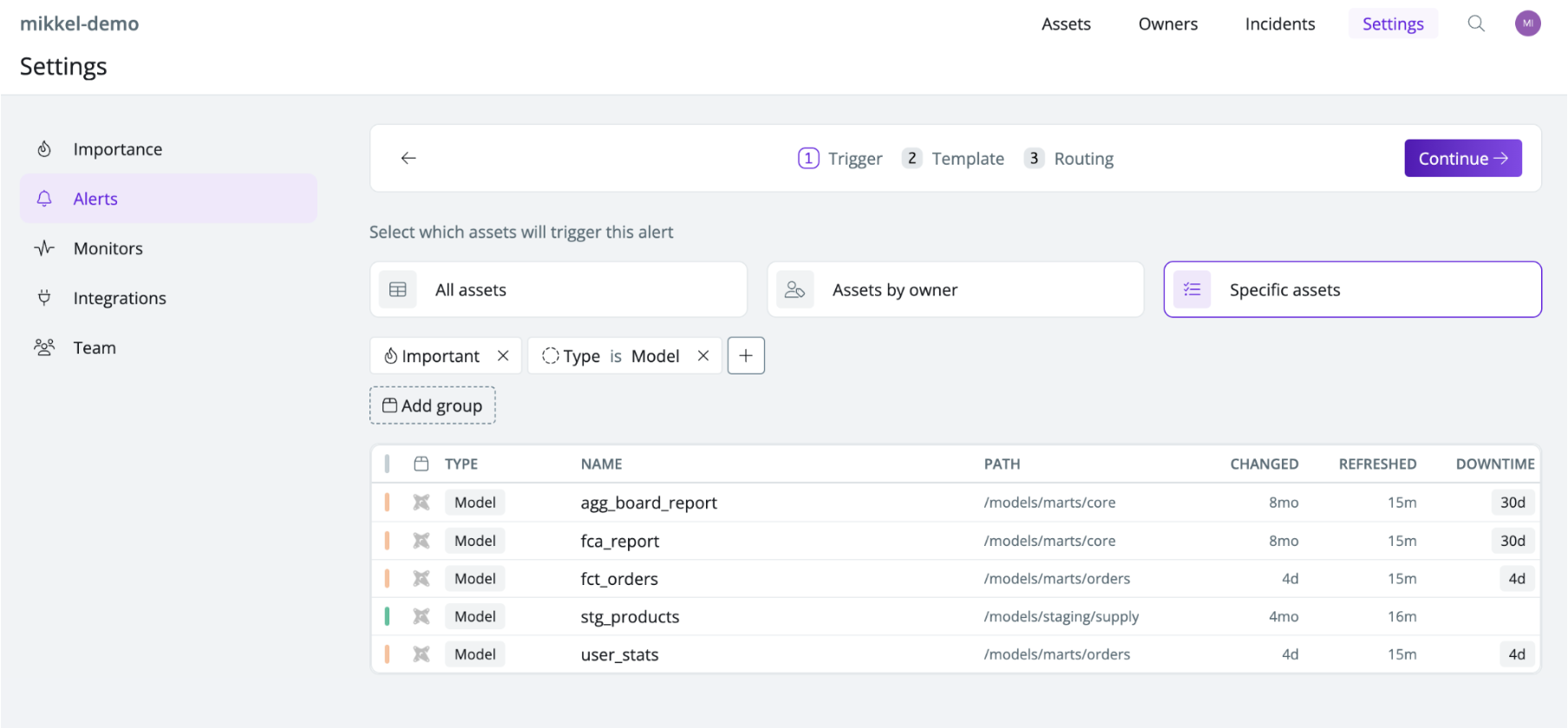
Example data alert from Synq sent to #p1-data-issues

SLAs and uptime monitoring
It can be a good idea to be specific about expectations for your most important data. This often involves data models that are enforced with data contracts. Doing this can help you set targets for where to improve and be transparent with other teams that interface with the data about the uptime they can expect.
In Synq, you can create views based on owner and criticality to get out-of-the-box SLA and uptime monitoring both on contract, model and test failures.
Summary
In this article we’ve looked at data contracts, why they’re useful and how to draw the boundaries across data, engineering and business teams.
- Issues introduced by upstream teams are often the most common cause of frustration for data teams
- Data contracts can help prevent unintended issues from sneaking into the data warehouse but companies are often overwhelmed by the technical and organisational burden of implementing them
- With dbt 1.5 you can enforce quality with data contracts at the model level and extend it with tests to distribute ownership to relevant teams. This can be a great way to circumvent the technical challenges of data contracts at the systems level
- You can use Synq to easily route alerts from tests and contract breaches to the relevant team and to monitor SLA and uptime of your most important data assets

.png)
.png)